最新发布
-
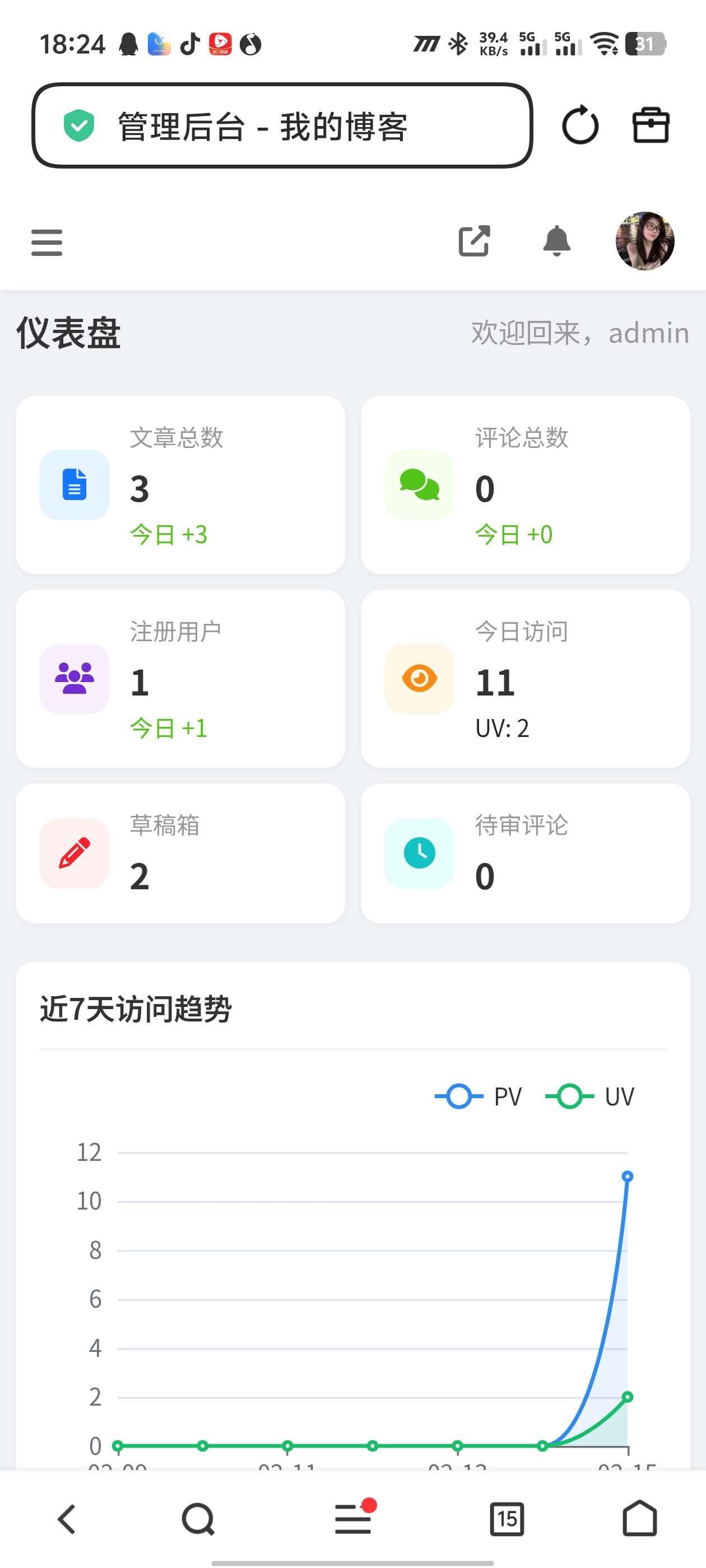
 GinCdn内容分发系统V1.0.2发布:企业级CDN架构迎来节点监控全面升级 GinCdn内容分发系统V1.0.2发布:企业级CDN架构迎来节点监控全面升级 引言 在当今互联网高速发展的时代,内容分发网络(CDN)已成为保障网站和应用高性能、高可用的基础设施。2026年3月16日,GinCdn内容分发系统正式发布V1.0.2版本,这是继3月6日V1.0.0版本和3月15日V1.0.1版本之后的又一次重要迭代。本次更新聚焦节点监控体系的全方位升级,为企业用户提供了更精细、更实时的边缘节点运维能力。 gincdn透明.png图片 本文将深入解析GinCdn V1.0.2的核心特性,并从架构设计、部署实践、运维管理三个维度,全面剖析这款基于Gin框架构建的商业CDN系统。 一、GinCdn系统概述 1.1 什么是GinCdn? GinCdn是一款基于Go语言Gin框架开发的企业级内容分发系统,旨在为用户提供智能调度、高效缓存、精准监控的一体化CDN解决方案。系统采用主控+边缘节点的分布式架构,主控端负责配置管理、智能调度和业务运营,边缘节点负责内容缓存和请求响应。 1.2 系统核心优势 高性能架构:基于Gin框架的高并发能力,单节点可承载数万QPS 智能调度:支持区域线路解析,根据用户地理位置智能分配最优节点 完整运营体系:内置套餐管理、角色折扣、支付集成,可直接开展CDN业务 企业级安全:全局防火墙、证书上传、HTTPS加速全方位保障 精细化监控:V1.0.2新增的节点监控体系,实现节点状态实时可感知 二、V1.0.2版本核心特性解析 本次版本更新聚焦节点监控领域,新增四大核心功能,让我们逐一解读。 2.1 新增节点监控日志 功能描述:系统现在会详细记录每个边缘节点的运行日志,包括CPU使用率、内存占用、磁盘IO、网络流量、请求响应时间等关键指标。 4.png图片 技术价值: 故障溯源:当节点出现异常时,可通过监控日志快速定位问题根源 性能分析:基于历史日志数据,分析节点负载规律,为容量规划提供依据 审计合规:完整的日志记录满足企业审计和合规要求 应用场景:运维人员登录主控后台,进入"节点管理-监控日志"即可查看所有节点的历史运行状态,支持按时间、节点、指标类型等多维度筛选。 2.2 新增节点监控配置 功能描述:管理员可在主控端灵活配置监控策略,包括监控指标阈值、采样频率、告警触发条件等。 1.png图片 技术价值: 灵活适配:不同业务场景对监控的要求不同,可配置化满足个性化需求 资源优化:合理设置采样频率,在监控精度和系统开销间取得平衡 智能告警:基于阈值配置,实现异常状态的自动识别 2.3 新增节点实时状态 功能描述:主控端现在可以实时获取所有边缘节点的当前运行状态,包括在线/离线状态等动态信息。 2.png图片 技术价值: 实时调度:负载均衡模块可根据节点实时状态,动态调整流量分配 快速响应:当节点出现异常时,可立即发现并触发告警或自动切换 可视化运维:主控后台以图表形式直观展示节点状态,运维体验大幅提升 实现原理:边缘节点通过心跳机制定期向主控端上报状态信息,V1.0.2优化了心跳协议,将上报频率提升至秒级,同时引入增量上报机制,大幅降低网络开销。 2.4 新增节点通知配置 功能描述:当节点发生状态变化(如离线、恢复、过载)或触发监控阈值时,系统可通过多种渠道发送通知。 3.png图片 技术价值: 多渠道告警:支持邮件、等多种通知方式 分级通知:可根据事件严重级别,设置不同的通知策略和接收人 告警静默:避免重复告警的打扰,支持告警静默期配置 三、系统架构深度解析 3.1 整体架构 GinCdn采用经典的主控-边缘两级架构: ┌─────────────────────────────────────┐ │ 主控端(Master) │ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │ │配置管理│ │调度中心│ │监控系统│ │ │ └───────┘ └───────┘ └───────┘ │ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │ │运营系统│ │API网关│ │数据库 │ │ │ └───────┘ └───────┘ └───────┘ │ └────────────┬────────────────────────┘ │ 控制面(配置下发、状态上报) ┌────────┼────────┬────────┐ ▼ ▼ ▼ ▼ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │边缘节点1│ │边缘节点2│ │边缘节点3│ │边缘节点N│ │ 缓存服务 │ │ 缓存服务 │ │ 缓存服务 │ │ 缓存服务 │ └────────┘ └────────┘ └────────┘ └────────┘3.2 主控端核心模块 模块功能描述技术实现配置管理站点配置、缓存规则、安全策略的统一管理Gin框架 + MySQL调度中心智能DNS解析、负载均衡、流量调度基于地理位置和节点负载的调度算法监控系统节点监控、日志收集、告警通知V1.0.2核心升级模块运营系统套餐管理、订单处理、支付集成集成彩虹易支付API网关提供RESTful API供第三方调用Gin框架实现3.3 边缘节点核心功能 内容缓存:支持内存缓存和磁盘缓存两级架构 请求代理:缓存未命中时从源站拉取内容 SSL加速:支持证书上传和HTTPS卸载 状态上报:定期向主控端上报运行状态(V1.0.2优化) 配置同步:支持离线节点差量同步(V1.0.1新增) 四、部署实践指南 4.1 环境要求 主控端: 操作系统:CentOS 7.6+ / Ubuntu 18.04+ CPU:4核+ 内存:4GB+ 磁盘:20GB+ SSD 数据库:MySQL 5.6+ 边缘节点: 操作系统:CentOS 7.6+ / Ubuntu 18.04+ CPU:2核+ 内存:2GB+ 磁盘:20GB+ SSD(视缓存需求而定) 4.2 部署流程 步骤一:获取安装包 访问正版授权官网 auth.shuha.cn 或官网 www.gincdn.cn,下载最新版本安装包。 步骤二:部署主控端 # 解压安装包 tar -zxvf gincdn-master-v1.0.2.tar.gz cd gincdn-master # 运行安装脚本 ./install.sh # 根据提示配置数据库连接 # 设置管理员账号密码步骤三:部署边缘节点 # 解压节点安装包 tar -zxvf gincdn-node-v1.0.2.tar.gz cd gincdn-node # 运行安装脚本,输入主控端地址和认证密钥 ./install.sh --master=192.168.1.100:8080 --token=your_token步骤四:节点加入与管理 登录主控后台,进入"节点管理" 查看待审批的节点请求,点击"批准" 为主控节点分配线路标签(如"电信"、"移动"、"联通") 配置监控策略,启用V1.0.2新增的监控功能 五、运维管理最佳实践 5.1 日常运维检查清单 节点状态检查:查看节点实时状态,确认所有节点在线且负载正常 监控告警检查:查看近期告警记录,分析是否存在潜在问题 日志分析:定期检查节点监控日志,发现性能瓶颈 配置同步验证:确保配置更新已成功同步至所有节点 缓存命中率:监控缓存命中率,优化缓存策略 5.2 常见问题排查 问题1:节点状态显示离线 检查节点服务器网络连通性 检查防火墙是否放行通信端口 问题2:监控告警频繁触发 分析监控日志,确定是真实负载过高还是阈值设置过小 适当调整监控阈值,避免误告警 检查节点是否需要扩容 问题3:配置同步失败 检查主控端和被控节点的网络连接 查看节点是否有足够磁盘空间 手动触发同步:主控后台 → 节点管理 → 同步配置 六、未来展望 GinCdn自3月6日发布V1.0.0以来,短短10天内完成了两次重要迭代,产品迭代速度令人印象深刻。从功能演进轨迹可以看出开发团队的战略规划: V1.0.0:构建基础架构,完成核心功能 V1.0.1:优化同步机制,增强系统可靠性 V1.0.2:完善监控体系,提升运维体验 展望未来,我们期待GinCdn在以下方向继续发力: 边缘计算:在边缘节点支持更复杂的计算任务 智能缓存:基于机器学习的内容预加载策略 多云部署:支持主流云厂商的混合部署模式 安全增强:集成WAF、DDoS防护等安全能力 结语 GinCdn V1.0.2的发布,标志着这款新兴的CDN系统在运维监控层面达到了企业级产品的成熟度。新增的节点监控日志、监控配置、实时状态和通知配置四大功能,为运维人员提供了完整的可观测性体系,让CDN运维从被动救火转向主动预防。 对于正在寻求CDN解决方案或计划开展CDN业务的企业来说,GinCdn凭借其完整的运营体系和高性能架构,无疑是一个值得关注的选择。而基于Gin框架的纯Go实现,也保证了其在性能和资源消耗方面的优势。 官方网站:www.gincdn.cn 正版授权官网:auth.shuha.cn
GinCdn内容分发系统V1.0.2发布:企业级CDN架构迎来节点监控全面升级 GinCdn内容分发系统V1.0.2发布:企业级CDN架构迎来节点监控全面升级 引言 在当今互联网高速发展的时代,内容分发网络(CDN)已成为保障网站和应用高性能、高可用的基础设施。2026年3月16日,GinCdn内容分发系统正式发布V1.0.2版本,这是继3月6日V1.0.0版本和3月15日V1.0.1版本之后的又一次重要迭代。本次更新聚焦节点监控体系的全方位升级,为企业用户提供了更精细、更实时的边缘节点运维能力。 gincdn透明.png图片 本文将深入解析GinCdn V1.0.2的核心特性,并从架构设计、部署实践、运维管理三个维度,全面剖析这款基于Gin框架构建的商业CDN系统。 一、GinCdn系统概述 1.1 什么是GinCdn? GinCdn是一款基于Go语言Gin框架开发的企业级内容分发系统,旨在为用户提供智能调度、高效缓存、精准监控的一体化CDN解决方案。系统采用主控+边缘节点的分布式架构,主控端负责配置管理、智能调度和业务运营,边缘节点负责内容缓存和请求响应。 1.2 系统核心优势 高性能架构:基于Gin框架的高并发能力,单节点可承载数万QPS 智能调度:支持区域线路解析,根据用户地理位置智能分配最优节点 完整运营体系:内置套餐管理、角色折扣、支付集成,可直接开展CDN业务 企业级安全:全局防火墙、证书上传、HTTPS加速全方位保障 精细化监控:V1.0.2新增的节点监控体系,实现节点状态实时可感知 二、V1.0.2版本核心特性解析 本次版本更新聚焦节点监控领域,新增四大核心功能,让我们逐一解读。 2.1 新增节点监控日志 功能描述:系统现在会详细记录每个边缘节点的运行日志,包括CPU使用率、内存占用、磁盘IO、网络流量、请求响应时间等关键指标。 4.png图片 技术价值: 故障溯源:当节点出现异常时,可通过监控日志快速定位问题根源 性能分析:基于历史日志数据,分析节点负载规律,为容量规划提供依据 审计合规:完整的日志记录满足企业审计和合规要求 应用场景:运维人员登录主控后台,进入"节点管理-监控日志"即可查看所有节点的历史运行状态,支持按时间、节点、指标类型等多维度筛选。 2.2 新增节点监控配置 功能描述:管理员可在主控端灵活配置监控策略,包括监控指标阈值、采样频率、告警触发条件等。 1.png图片 技术价值: 灵活适配:不同业务场景对监控的要求不同,可配置化满足个性化需求 资源优化:合理设置采样频率,在监控精度和系统开销间取得平衡 智能告警:基于阈值配置,实现异常状态的自动识别 2.3 新增节点实时状态 功能描述:主控端现在可以实时获取所有边缘节点的当前运行状态,包括在线/离线状态等动态信息。 2.png图片 技术价值: 实时调度:负载均衡模块可根据节点实时状态,动态调整流量分配 快速响应:当节点出现异常时,可立即发现并触发告警或自动切换 可视化运维:主控后台以图表形式直观展示节点状态,运维体验大幅提升 实现原理:边缘节点通过心跳机制定期向主控端上报状态信息,V1.0.2优化了心跳协议,将上报频率提升至秒级,同时引入增量上报机制,大幅降低网络开销。 2.4 新增节点通知配置 功能描述:当节点发生状态变化(如离线、恢复、过载)或触发监控阈值时,系统可通过多种渠道发送通知。 3.png图片 技术价值: 多渠道告警:支持邮件、等多种通知方式 分级通知:可根据事件严重级别,设置不同的通知策略和接收人 告警静默:避免重复告警的打扰,支持告警静默期配置 三、系统架构深度解析 3.1 整体架构 GinCdn采用经典的主控-边缘两级架构: ┌─────────────────────────────────────┐ │ 主控端(Master) │ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │ │配置管理│ │调度中心│ │监控系统│ │ │ └───────┘ └───────┘ └───────┘ │ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │ │运营系统│ │API网关│ │数据库 │ │ │ └───────┘ └───────┘ └───────┘ │ └────────────┬────────────────────────┘ │ 控制面(配置下发、状态上报) ┌────────┼────────┬────────┐ ▼ ▼ ▼ ▼ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │边缘节点1│ │边缘节点2│ │边缘节点3│ │边缘节点N│ │ 缓存服务 │ │ 缓存服务 │ │ 缓存服务 │ │ 缓存服务 │ └────────┘ └────────┘ └────────┘ └────────┘3.2 主控端核心模块 模块功能描述技术实现配置管理站点配置、缓存规则、安全策略的统一管理Gin框架 + MySQL调度中心智能DNS解析、负载均衡、流量调度基于地理位置和节点负载的调度算法监控系统节点监控、日志收集、告警通知V1.0.2核心升级模块运营系统套餐管理、订单处理、支付集成集成彩虹易支付API网关提供RESTful API供第三方调用Gin框架实现3.3 边缘节点核心功能 内容缓存:支持内存缓存和磁盘缓存两级架构 请求代理:缓存未命中时从源站拉取内容 SSL加速:支持证书上传和HTTPS卸载 状态上报:定期向主控端上报运行状态(V1.0.2优化) 配置同步:支持离线节点差量同步(V1.0.1新增) 四、部署实践指南 4.1 环境要求 主控端: 操作系统:CentOS 7.6+ / Ubuntu 18.04+ CPU:4核+ 内存:4GB+ 磁盘:20GB+ SSD 数据库:MySQL 5.6+ 边缘节点: 操作系统:CentOS 7.6+ / Ubuntu 18.04+ CPU:2核+ 内存:2GB+ 磁盘:20GB+ SSD(视缓存需求而定) 4.2 部署流程 步骤一:获取安装包 访问正版授权官网 auth.shuha.cn 或官网 www.gincdn.cn,下载最新版本安装包。 步骤二:部署主控端 # 解压安装包 tar -zxvf gincdn-master-v1.0.2.tar.gz cd gincdn-master # 运行安装脚本 ./install.sh # 根据提示配置数据库连接 # 设置管理员账号密码步骤三:部署边缘节点 # 解压节点安装包 tar -zxvf gincdn-node-v1.0.2.tar.gz cd gincdn-node # 运行安装脚本,输入主控端地址和认证密钥 ./install.sh --master=192.168.1.100:8080 --token=your_token步骤四:节点加入与管理 登录主控后台,进入"节点管理" 查看待审批的节点请求,点击"批准" 为主控节点分配线路标签(如"电信"、"移动"、"联通") 配置监控策略,启用V1.0.2新增的监控功能 五、运维管理最佳实践 5.1 日常运维检查清单 节点状态检查:查看节点实时状态,确认所有节点在线且负载正常 监控告警检查:查看近期告警记录,分析是否存在潜在问题 日志分析:定期检查节点监控日志,发现性能瓶颈 配置同步验证:确保配置更新已成功同步至所有节点 缓存命中率:监控缓存命中率,优化缓存策略 5.2 常见问题排查 问题1:节点状态显示离线 检查节点服务器网络连通性 检查防火墙是否放行通信端口 问题2:监控告警频繁触发 分析监控日志,确定是真实负载过高还是阈值设置过小 适当调整监控阈值,避免误告警 检查节点是否需要扩容 问题3:配置同步失败 检查主控端和被控节点的网络连接 查看节点是否有足够磁盘空间 手动触发同步:主控后台 → 节点管理 → 同步配置 六、未来展望 GinCdn自3月6日发布V1.0.0以来,短短10天内完成了两次重要迭代,产品迭代速度令人印象深刻。从功能演进轨迹可以看出开发团队的战略规划: V1.0.0:构建基础架构,完成核心功能 V1.0.1:优化同步机制,增强系统可靠性 V1.0.2:完善监控体系,提升运维体验 展望未来,我们期待GinCdn在以下方向继续发力: 边缘计算:在边缘节点支持更复杂的计算任务 智能缓存:基于机器学习的内容预加载策略 多云部署:支持主流云厂商的混合部署模式 安全增强:集成WAF、DDoS防护等安全能力 结语 GinCdn V1.0.2的发布,标志着这款新兴的CDN系统在运维监控层面达到了企业级产品的成熟度。新增的节点监控日志、监控配置、实时状态和通知配置四大功能,为运维人员提供了完整的可观测性体系,让CDN运维从被动救火转向主动预防。 对于正在寻求CDN解决方案或计划开展CDN业务的企业来说,GinCdn凭借其完整的运营体系和高性能架构,无疑是一个值得关注的选择。而基于Gin框架的纯Go实现,也保证了其在性能和资源消耗方面的优势。 官方网站:www.gincdn.cn 正版授权官网:auth.shuha.cn
-
东方博客1.0重磅开源:打造高并发、易扩展的现代化PHP博客系统 东方博客1.0重磅开源:打造高并发、易扩展的现代化PHP博客系统 专为高流量场景优化,内置微信公众号与智能采集插件,开启高效内容创作与运营新体验在内容为王的时代,一个稳定、高效且功能强大的博客系统,是创作者、开发者和企业展示思想、沉淀知识、连接用户的核心阵地。今天,我们非常荣幸地宣布:经过持续打磨与全场景优化的 东方博客1.0 正式全网开源!这不仅是一套代码,更是一个集成了高并发能力、强大扩展性和智能运营工具的完整内容管理解决方案。 1FE8E44438185F00A13229918F5A9F04.jpg图片 CBF183BC5BAEEA82E44C13B01D195CFA.jpg图片 🚀 项目源码: 隐藏内容,请前往内页查看详情 🎯 核心定位:为性能与扩展而生 东方博客1.0从设计之初,就将高并发响应和二次开发友好作为核心理念。它依托经典的 PHP + MySQL 架构,通过一系列深度优化,确保系统在面对日常访问或流量峰值时,都能保持稳定、快速的运行状态。 高并发保障:系统通过数据库索引优化、多级缓存机制落地以及代码模块化分层,全方位提升并发处理能力。 现代化管理:配备响应式后台,完美适配PC与移动端。侧边栏智能折叠、分类层级可视化管理、数据可视化统计等功能,让内容管理变得直观高效。 清晰易扩展:代码结构清晰、注释完善,严格遵循开发规范,核心逻辑充分解耦,无论是学习研究还是进行深度二次开发,都能轻松上手。 ✨ 核心功能模块 系统内置了博客运营所需的核心功能,开箱即用: 内容发布与管理:支持文章发布、分类管理、标签系统,提供流畅的写作体验。 多角色权限控制:可灵活分配管理员、编辑、作者等不同角色权限。 SEO精准优化:内置SEO配置模块,助力文章在搜索引擎中获得更好排名。 插件商店架构:预留插件接口,未来可方便地扩展功能。 🔥 本次开源的两大重磅插件 这是东方博客1.0区别于其他博客系统的亮点所在,它们将极大提升您的内容运营效率: 1. 微信公众号专属插件:打通内容双向闭环 核心价值:实现博客与公众号的无缝连接。您在博客发布的内容,可以自动同步推送到公众号;公众号内的用户互动和数据,也能回流至博客系统。 运营助力:轻松实现“一处发布,多端触达”,大幅提升内容曝光率和用户留存效率,构建私域流量闭环。 2. 智能采集插件:快速填充内容库 核心价值:支持多源内容智能采集,您可以通过自定义规则,从指定网站抓取内容。 智能处理:系统具备去重清洗和定时发布功能,可一键整合优质行业内容,快速丰富博客素材库。 合规保障:插件支持原创内容标记,方便您在利用公开信息的同时,兼顾内容合规性。 📦 获取与使用 您可以通过以下链接获取完整的系统源码: 下载地址: 隐藏内容,请前往内页查看详情 部署简述: 作为标准的PHP应用,部署过程友好。通常您需要: 将程序文件上传至支持 PHP 7.4+ 和 MySQL 5.7+ 的服务器。 根据安装向导,完成数据库配置。 访问后台(通常为 /admin)进行初始化设置。 ⚠️ 重要说明: 开发者明确声明:不再对本次开源的系统提供技术支持和程序维护。此举旨在鼓励广大开发者自行进行二次开发、修复Bug和迭代功能,共同参与生态建设。请在使用前评估自身的技术能力。🛡️ 进阶保障:保护你的衍生创作 当您基于东方博客1.0进行深度定制,并将其应用于商业项目或作为产品二次分发时,保护您的劳动成果至关重要: 1. PHP代码加密平台 (php.javait.cn):您开发的商业插件或核心定制逻辑,可以使用该平台提供的 SG16、Deck3 等多种算法进行代码加密,有效防止核心代码被轻易反编译和复制。 2. 数哈多应用授权系统 (auth.shuha.cn):若您将优化后的东方博客作为标准产品出售,该系统能帮助您实现专业的软件授权管理,如绑定域名、设置使用有效期等,将技术能力转化为可持续的软件收益。 🚀 未来展望:东方开源生态启航 东方博客1.0的开源,只是一个开始。开发者还透露了令人期待的计划: 东方云权通商城系统:正在紧锣密鼓开发中,预计1-4个月后开源。该系统将“对标电商平台,结合虚拟数字产品功能”,采用卖家入驻、充值推广的独特模式,功能全面,值得期待。 更多项目:包括东方壁纸系统配套的C语言客户端、易支付、API管理系统、音乐APP等,虽本次暂不发布,但展现了活跃的创作生态。 💎 总结:为创作者和开发者准备的礼物 东方博客1.0 的发布,为PHP开源社区贡献了一个高性能、功能强大且极具运营思维的博客系统。它既适合个人博主构建稳定高效的专属领地,也适合开发者作为学习高并发架构和二次开发的优秀范本。 立即下载,探索其强大功能,并期待您能基于它创造出更多精彩的应用。让我们共同完善这个开源生态,惠及更多创作者!
-
GinCdn内容分发系统(V1.0.1)详解+完整部署教程(主控+被控节点) GinCdn内容分发系统(V1.0.1)详解+完整部署教程(主控+被控节点) 前言:随着中小网站、个人项目的流量增长,自建CDN成为降低带宽成本、提升访问速度的优选方案。GinCdn作为基于Go语言开发的轻量、高性能自研CDN系统,凭借简洁的部署流程、丰富的功能支持,成为中小企业和个人开发者的得力工具。本文将详细介绍GinCdn的版本更新亮点,并手把手教你完成主控端与被控节点端的完整部署,全程实操无冗余,新手也能快速上手。 gincdn透明.png图片 一、GinCdn系统简介 GinCdn是一款基于Go语言(依托Gin框架高性能特性)开发的私有CDN内容分发系统,支持多节点部署、域名解析、缓存管理、支付集成等核心功能,无需复杂的技术储备,即可快速搭建属于自己的CDN网络,适用于个人站长、中小企事业单位,可有效优化网站访问速度、降低源站压力。 官方授权站:auth.shuha.cn(获取正版授权、最新源码及相关资源) 二、GinCdn版本更新日志(V1.0.0-V1.0.1) GinCdn迭代速度较快,近期已更新至V1.0.1版本,重点优化节点同步与管理功能,以下是完整更新记录,方便大家了解功能迭代方向,适配对应版本部署。 V1.0.1(2026.03.15)—— 节点管理优化版 本次更新聚焦节点同步与日志管理,解决离线节点同步效率低、节点状态难监控等问题,进一步提升系统稳定性,新增功能如下: 新增离线节点差量同步:无需全量同步所有数据,仅同步离线期间变化的内容,大幅提升同步效率,降低服务器带宽占用,尤其适合多节点分布式部署场景。 新增节点日志记录表:实时记录节点的运行状态、同步记录、异常信息,便于开发者快速排查节点连接、缓存同步等问题,降低运维成本。 新增线路节点异步同步:采用异步机制处理线路与节点的同步操作,不阻塞主进程,提升系统整体响应速度,避免因同步操作导致的卡顿。 新增当前在线节点获取:可在主控端实时查看所有在线节点列表,清晰掌握节点运行状态,便于节点的批量管理与维护。 V1.0.0(2026.03.06)—— 基础功能完整版 初始稳定版本,搭建了GinCdn的核心架构,涵盖CDN运行所需的基础功能,具体如下: 支持阿里云DNS:可快速对接阿里云DNS,实现域名解析的自动化配置,无需手动操作解析记录。 支持多节点部署:可部署多个被控节点,实现多地区内容分发,进一步优化不同地域用户的访问体验。 支持彩虹易支付:集成彩虹易支付接口,可实现CDN套餐的付费购买、续费等功能,适合商业化运营。 支持套餐分类与设置:可根据用户需求,自定义CDN套餐(如带宽、缓存容量、有效期等),灵活适配不同用户场景。 支持邮箱发信:可配置邮箱服务,实现用户注册通知、套餐到期提醒、异常告警等邮件推送功能。 支持全局防火墙配置:可设置全局防火墙规则,拦截恶意访问,保护CDN节点与源站安全。 支持全局Nginx配置:可统一配置所有节点的Nginx参数,无需逐个节点修改,提升运维效率。 缓存、默认页、错误页配置:可自定义缓存规则、默认访问页面、错误页面,优化用户访问体验。 支持角色折扣功能:可设置不同角色(如普通用户、VIP用户)的套餐折扣,提升用户粘性。 支持证书上传:可上传SSL证书,实现HTTPS加密访问,保障数据传输安全。 支持区域线路解析:可根据用户地域,自动分配最近的CDN节点,最大化提升访问速度。 支持站点接入:可快速接入多个网站,实现多站点的CDN加速管理,一站式运维。 支持同步配置:可实现主控端与被控节点的配置同步,修改主控端配置后,节点自动同步更新,无需手动操作。 三、部署前置准备(必看) 部署前需准备好相关服务器、软件及资源,避免部署过程中出现卡顿、失败等问题,以下是详细准备清单,适配V1.0.1版本。 3.1 服务器要求 主控端:CentOS 7.6–7.9 / Ubuntu 18.04-22.04(推荐2核4G及以上,确保网络通畅,带宽≥10M); 被控节点(边缘节点):CentOS 7+/Ubuntu 20.04+(推荐1核2G及以上,带宽≥5M,可部署多个节点,分布在不同地域效果更佳); 网络要求:主控端与被控节点可相互访问,防火墙放行相关端口(后续会详细说明)。 3.2 软件与资源准备 通用软件:宝塔面板V11.0+(可视化运维,降低部署难度,新手首选); 主控端依赖:Nginx 1.18+、MySQL 5.6+、Go 1.19+; 被控节点依赖:Go 1.19+、Nginx(无需MySQL,仅需基础运行环境); 核心资源:GinCdn V1.0.1 主控端源码、被控节点程序(从官方授权站auth.shuha.cn获取); 其他资源:域名1个(已解析到主控端服务器IP)、GinCdn官方授权码(从官方授权站获取)、SSL证书(可选,用于HTTPS访问)。 3.3 环境预处理 所有服务器安装宝塔面板,安装完成后,登录宝塔面板,安装所需软件(Nginx、MySQL); 放行运行端口(宝塔面板 → 安全 → 放行端口); 确保主控端MySQL服务正常运行,创建数据库时记录好账号密码,后续配置会用到。 四、主控端部署(宝塔面板,V1.0.1版本) 主控端是GinCdn的核心管理端,负责节点管理、配置设置、用户管理等功能,部署流程全程可视化,新手可直接跟着操作。 步骤1:创建数据库 登录宝塔面板,点击左侧「数据库」→「添加数据库」; 填写数据库信息(建议统一规范,便于后续维护): 数据库名:gincdn_db(可自定义,建议包含gincdn标识); 用户名:gincdn_user(可自定义); 密码:设置复杂密码(建议包含字母、数字、特殊符号); 字符集:utf8mb4(兼容所有字符,避免中文乱码); 点击「创建」,创建完成后,记录好数据库名、用户名、密码,后续配置会用到。 步骤2:上传并解压GinCdn主控端源码 从官方授权站auth.shuha.cn下载GinCdn V1.0.1主控端源码压缩包(格式为zip/tar.gz); 登录宝塔面板,点击左侧「文件」→「新建目录」,目录路径设置为「/wwwroot/gincdn」(可自定义,建议放在/wwwroot目录下); 进入「/wwwroot/gincdn」目录,点击「上传」,选择下载好的源码压缩包,上传完成后,点击「解压」,将源码解压到该目录; 解压完成后,检查目录结构,确保包含gincdn(主程序)、config.yaml(配置文件)、gincdn.sql(数据库脚本)三个核心文件,缺一不可。 步骤3:编辑配置文件config.yaml 配置文件是主控端运行的核心,需根据实际环境修改,具体步骤如下: 进入「/wwwroot/gincdn」目录,找到config.yaml文件,点击「编辑」; 按照以下示例修改配置(替换括号内的内容,其他参数默认即可): port: 8080 # 主控端运行端口,确保未被占用(如已占用,可修改为其他端口) db: host: localhost # 数据库地址,本地部署填写localhost即可 port: 3306 # 数据库端口,默认3306 name: gincdn_db # 步骤1创建的数据库名 user: gincdn_user # 步骤1创建的数据库用户名 pass: 你的数据库密码 # 步骤1设置的数据库密码 auth: 你的官方授权码 # 从auth.shuha.cn获取的授权码 修改完成后,点击「保存」,关闭编辑界面。 步骤4:导入数据库脚本 登录宝塔面板,点击左侧「数据库」→ 找到步骤1创建的gincdn_db数据库,点击「导入」; 点击「选择文件」,找到「/wwwroot/gincdn」目录下的gincdn.sql文件,选中后点击「执行」; 导入完成后,会提示「导入成功」,若提示失败,检查数据库字符集是否为utf8mb4,或脚本文件是否完整。 步骤5:启动GinCdn主控端 登录宝塔面板,点击左侧「网站」→「Go项目」→「添加」; 填写Go项目信息: 项目名称:GinCdn主控端(可自定义); 项目目录:选择「/wwwroot/gincdn」; 运行命令:go run main.go; 端口:填写config.yaml中设置的端口(默认8080); 点击「启动」,启动成功后,会提示「启动成功」; 验证启动是否成功:打开浏览器,输入「http://主控IP:8080」或「https://你的主控域名」,能看到GinCdn首页,即启动成功。 步骤6:登录主控端后台 管理员后台:访问「http://主控域名/admin」或「http://主控IP:8080/admin」,默认账号:admin,默认密码:123456; 用户端后台:访问「http://主控域名/user」或「http://主控IP:8080/user」,供普通用户登录使用; 首次登录后,建议立即修改管理员密码,提升安全性,同时进入「系统设置」,检查授权码、域名等配置是否正确。 五、被控节点端部署(通用版,适配V1.0.1) GinCdn内容分发系统Ubuntu18-24被控节点部署安装教程 GinCdn是一款轻量级的内容分发系统,本文将详细讲解在Ubuntu 18.04~24.04系统中,如何快速部署GinCdn被控节点,全程通过命令行操作,新手也能轻松上手。 gincdn透明.png图片 一、部署前准备 1. 环境要求 系统版本:Ubuntu 18.04/20.04/22.04/24.04(64位) 网络要求:服务器可访问公网,且80/443/8080端口(根据主控端配置)可正常通信 配置要求:2H2G、2H4G、4H4G、4H8G、8H2G、8H4G、8H8G、8H16G、16H16G、16H2G、16H4G、16H8G、16H32G等规格(根据业务负载选择) 权限要求:使用 root 用户执行命令(非 root 需在命令前加sudo) 2. 基础依赖检查 提前安装基础网络工具(可选,脚本会自动安装): apt update -y && apt install -y curl wget二、一键部署步骤 1. 下载部署脚本 执行以下命令下载官方部署脚本,并赋予执行权限(核心命令,解决HTTP/2协议兼容问题): curl -k --http1.1 -o /root/start.sh https://www.gincdn.cn/download/ubuntu/start.sh && chmod +x /root/start.sh执行成功标志: % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 10932 100 10932 0 0 254k 0 --:--:-- --:--:-- --:--:-- 254k显示100%下载完成且无报错,说明脚本下载成功。 2. 运行部署脚本 执行下载好的脚本,启动全自动部署流程: /root/start.sh3. 配置主控地址 脚本执行过程中会提示输入主控地址,格式示例:http://192.168.1.100:8080(替换为你的实际主控端地址): 三、部署结果验证 1. 检查服务状态 执行以下命令查看GinCdn节点服务状态: systemctl status ws_config_client.service成功标志:输出中包含Active: active (running),示例: ● ws_config_client.service - GinCDN WS配置客户端服务 Loaded: loaded (/etc/systemd/system/ws_config_client.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2026-03-07 17:48:08 UTC; 1min ago Main PID: 118070 (bash) Tasks: 5 (limit: 9507) Memory: 13.3M CGroup: /system.slice/ws_config_client.service └─118070 /bin/bash /opt/gincdn/ws_config_client.sh2. 验证主控地址配置 检查配置文件中主控地址是否正确: grep MASTER_API_URL /opt/gincdn/conf/node_config.conf成功标志:输出显示你配置的主控地址,示例: MASTER_API_URL="http://192.168.1.100:8080"3. 检查开机自启 确认服务已配置开机自启: systemctl is-enabled ws_config_client.service成功标志:输出enabled。 四、常见问题解决 1. 脚本下载失败(curl: (92) HTTP/2 stream 0 was not closed cleanly) 原因:目标服务器HTTP/2协议兼容问题,解决方案:使用--http1.1参数强制HTTP/1.1协议(本文核心命令已包含)。 2. 解压失败(unzip: command not found) 原因:未安装unzip工具,解决方案: apt install -y unzip3. 服务启动失败(Active: inactive (dead)) 解决方案: # 重新加载服务配置 systemctl daemon-reload # 重启服务 systemctl restart ws_config_client.service 4. 主控地址配置错误 修改配置文件并重启服务: # 编辑配置文件 sed -i "s|MASTER_API_URL=\".*\"|MASTER_API_URL=\"新主控地址\"|g" /opt/gincdn/conf/node_config.conf # 重启服务 systemctl restart ws_config_client.service五、日常运维命令 1. 服务启停 # 启动服务 systemctl start ws_config_client.service # 停止服务 systemctl stop ws_config_client.service # 重启服务 systemctl restart ws_config_client.service2. 卸载节点(可选) # 停止服务 systemctl stop ws_config_client.service # 禁用开机自启 systemctl disable ws_config_client.service # 删除相关文件 rm -rf /root/gincdn.sh /opt/gincdn /etc/systemd/system/ws_config_client.service # 重新加载服务配置 systemctl daemon-reload总结 GinCdn 被控节点在 Ubuntu 18~24 系统中的部署流程高度自动化,核心步骤仅需「下载脚本→运行脚本→配置主控地址」三步,全程无需手动修改配置文件。部署完成后重点验证服务是否为active (running)状态,确保节点与主控端正常通信。该部署方案适配全版本 Ubuntu 系统,不同配置的服务器均可按需部署,满足各类内容分发场景的需求 六、V1.0.1版本新增功能使用说明 部署完成后,可重点体验V1.0.1版本的新增功能,提升节点管理效率,以下是核心功能的使用方法: 离线节点差量同步 当节点因网络问题离线后,重新上线时,系统会自动触发差量同步,仅同步离线期间主控端修改的配置、新增的缓存内容,无需全量同步,节省带宽和时间。可在主控端「节点管理」→「节点详情」中,查看同步记录。 节点日志记录表 登录主控端管理员后台,点击左侧「日志管理」→「节点日志」,可查看所有节点的运行日志,包括同步记录、异常信息、访问记录等,支持按节点、时间筛选,快速排查问题。 线路节点异步同步 系统默认开启异步同步,修改主控端线路配置、节点配置后,无需等待同步完成,可继续操作其他功能,同步过程在后台自动进行,不影响主控端正常运行。 当前在线节点获取 登录主控端管理员后台,点击左侧「节点管理」,可实时查看所有在线节点的列表,包括节点IP、地区、状态、缓存使用率等信息,便于批量管理和监控。 七、常见问题排查(新手必看) 部署过程中,可能会遇到一些小问题,以下是高频问题及解决方案,帮助大家快速排查,避免走弯路。 问题1:主控端启动失败 解决方案:1. 检查MySQL连接信息是否正确(config.yaml中的db配置);2. 检查8080端口是否被占用(宝塔面板→安全→端口占用,关闭占用端口的程序);3. 检查授权码是否正确,是否过期(可在官方授权站验证);4. 检查数据库脚本是否导入成功,重新导入gincdn.sql。 问题2:被控节点无法注册到主控端 解决方案:1. 检查主控端防火墙是否放行8080端口,节点服务器是否能ping通主控端IP;2. 检查节点安装命令是否正确,节点密钥是否填写错误;3. 检查节点服务器的环境是否安装成功;4. 检查节点配置文件中的主控端IP、端口是否正确。 问题3:访问加速域名提示异常 解决方案:1. 检查域名CNAME解析是否生效(可通过ping命令验证);2. 检查节点服务是否正常运行,状态是否为「在线」;3. 检查SSL证书是否上传成功,配置是否正确;4. 检查主控端全局防火墙是否拦截了访问请求。 八、生产环境优化建议 如果用于生产环境,建议做好以下优化,提升系统稳定性和安全性: 主控端:使用独立服务器,配置MySQL主从复制,定期备份数据库和配置文件,避免数据丢失; 被控节点:多地区部署节点(如华东、华北、华南),配置负载均衡,提升不同地域用户的访问速度; 安全防护:开启主控端和节点的防火墙,限制非法IP访问;定期更新GinCdn版本,修复已知漏洞;设置复杂的管理员密码,避免账号泄露; 监控告警:配置服务器监控(如宝塔面板监控、Zabbix),实时监控节点运行状态、带宽使用率、缓存容量,设置异常告警(如节点离线、缓存满); 带宽优化:根据节点访问量,合理调整缓存容量,定期清理过期缓存,释放磁盘空间。 九、总结 GinCdn V1.0.1版本在V1.0.0的基础上,重点优化了节点同步与日志管理功能,进一步提升了系统的稳定性和运维效率,部署流程简洁,无需复杂的技术储备,新手也能快速上手。通过本文的教程,你可以轻松完成主控端与被控节点的部署,搭建属于自己的私有CDN网络,有效优化网站访问速度、降低源站压力。 后续如果GinCdn更新新版本,或遇到部署、使用相关的问题,可访问官方授权站auth.shuha.cn获取帮助,也可以在评论区留言,一起交流探讨。 最后,觉得本文有用的话,记得点赞、收藏、关注,后续会持续更新GinCdn的使用技巧和优化方案! 补充说明 本文部署教程适配GinCdn V1.0.1版本,若使用其他版本,需根据版本差异调整配置和部署步骤; 所有命令均经过实测,若出现命令执行失败,可检查服务器系统版本、软件版本是否符合要求; 官方授权站auth.shuha.cn可获取最新源码、授权码及技术支持,建议优先从官方渠道获取资源,避免使用非官方版本导致的安全风险。
-
GinCdn内容分发系统Ubuntu18-24被控节点怎么部署安装? GinCdn内容分发系统Ubuntu18-24被控节点部署安装教程 GinCdn是一款轻量级的内容分发系统,本文将详细讲解在Ubuntu 18.04~24.04系统中,如何快速部署GinCdn被控节点,全程通过命令行操作,新手也能轻松上手。 gincdn透明.png图片 一、部署前准备 1. 环境要求 系统版本:Ubuntu 18.04/20.04/22.04/24.04(64位) 网络要求:服务器可访问公网,且80/443/8080端口(根据主控端配置)可正常通信 配置要求:2H2G、2H4G、4H4G、4H8G、8H2G、8H4G、8H8G、8H16G、16H16G、16H2G、16H4G、16H8G、16H32G等规格(根据业务负载选择) 权限要求:使用 root 用户执行命令(非 root 需在命令前加sudo) 2. 基础依赖检查 提前安装基础网络工具(可选,脚本会自动安装): apt update -y && apt install -y curl wget二、一键部署步骤 1. 下载部署脚本 执行以下命令下载官方部署脚本,并赋予执行权限(核心命令,解决HTTP/2协议兼容问题): curl -k --http1.1 -o /root/start.sh https://www.gincdn.cn/download/ubuntu/start.sh && chmod +x /root/start.sh执行成功标志: % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 10932 100 10932 0 0 254k 0 --:--:-- --:--:-- --:--:-- 254k显示100%下载完成且无报错,说明脚本下载成功。 2. 运行部署脚本 执行下载好的脚本,启动全自动部署流程: /root/start.sh3. 配置主控地址 脚本执行过程中会提示输入主控地址,格式示例:http://192.168.1.100:8080(替换为你的实际主控端地址): 三、部署结果验证 1. 检查服务状态 执行以下命令查看GinCdn节点服务状态: systemctl status ws_config_client.service成功标志:输出中包含Active: active (running),示例: ● ws_config_client.service - GinCDN WS配置客户端服务 Loaded: loaded (/etc/systemd/system/ws_config_client.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2026-03-07 17:48:08 UTC; 1min ago Main PID: 118070 (bash) Tasks: 5 (limit: 9507) Memory: 13.3M CGroup: /system.slice/ws_config_client.service └─118070 /bin/bash /opt/gincdn/ws_config_client.sh2. 验证主控地址配置 检查配置文件中主控地址是否正确: grep MASTER_API_URL /opt/gincdn/conf/node_config.conf成功标志:输出显示你配置的主控地址,示例: MASTER_API_URL="http://192.168.1.100:8080"3. 检查开机自启 确认服务已配置开机自启: systemctl is-enabled ws_config_client.service成功标志:输出enabled。 四、常见问题解决 1. 脚本下载失败(curl: (92) HTTP/2 stream 0 was not closed cleanly) 原因:目标服务器HTTP/2协议兼容问题,解决方案:使用--http1.1参数强制HTTP/1.1协议(本文核心命令已包含)。 2. 解压失败(unzip: command not found) 原因:未安装unzip工具,解决方案: apt install -y unzip3. 服务启动失败(Active: inactive (dead)) 解决方案: # 重新加载服务配置 systemctl daemon-reload # 重启服务 systemctl restart ws_config_client.service 4. 主控地址配置错误 修改配置文件并重启服务: # 编辑配置文件 sed -i "s|MASTER_API_URL=\".*\"|MASTER_API_URL=\"新主控地址\"|g" /opt/gincdn/conf/node_config.conf # 重启服务 systemctl restart ws_config_client.service五、日常运维命令 1. 服务启停 # 启动服务 systemctl start ws_config_client.service # 停止服务 systemctl stop ws_config_client.service # 重启服务 systemctl restart ws_config_client.service2. 卸载节点(可选) # 停止服务 systemctl stop ws_config_client.service # 禁用开机自启 systemctl disable ws_config_client.service # 删除相关文件 rm -rf /root/gincdn.sh /opt/gincdn /etc/systemd/system/ws_config_client.service # 重新加载服务配置 systemctl daemon-reload总结 GinCdn 被控节点在 Ubuntu 18~24 系统中的部署流程高度自动化,核心步骤仅需「下载脚本→运行脚本→配置主控地址」三步,全程无需手动修改配置文件。部署完成后重点验证服务是否为active (running)状态,确保节点与主控端正常通信。该部署方案适配全版本 Ubuntu 系统,不同配置的服务器均可按需部署,满足各类内容分发场景的需求
-
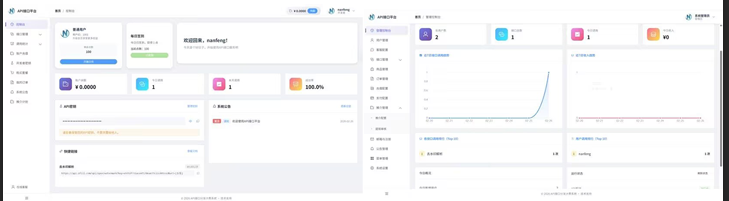
API灵钥系统全面升级:基于Java 17 + Vue3重构,打造更强大、更安全的API交易平台 API灵钥系统全面升级:基于Java 17 + Vue3重构,打造更强大、更安全的API交易平台 新增卡密兑换、IP白名单、推介分润,支持会员/点数/余额混合计费,手机电脑全适配在API经济蓬勃发展的今天,一套功能完善、安全可靠的API交易与管理平台,对于开发者、创业者和企业而言价值巨大。今天,我们为大家带来 API灵钥系统的全面升级版本。这套系统从底层架构到前端界面进行了彻底重构,旨在提供一个功能强大、易于扩展且体验现代化的API交易与管理解决方案。 1.png图片 2.png图片 全新技术栈:高性能与现代化兼备 本次升级最核心的变化是技术栈的全面革新,为系统的性能、安全性和可维护性奠定了坚实基础。 层级技术选型核心优势后端核心Java 17 + Spring Boot享受最新LTS版本的性能与安全更新,Spring Boot提供稳定高效的开发底座。ORM框架MyBatis-Plus简化数据库操作,提升开发效率,同时保证复杂查询的灵活性。权限与安全Sa-Token轻量级、功能强大的权限框架,轻松搞定登录认证、权限拦截。缓存与消息Redis + RabbitMQRedis保障高并发下的数据缓存,RabbitMQ处理异步任务,提升系统响应速度。数据库MySQL成熟稳定的关系型数据库,支撑核心业务数据存储。前端Vue3 + Element Plus + Vite现代化前端技术栈,带来流畅的用户交互体验和极速的开发构建。UI设计自适配精心设计的UI,在手机、平板和电脑端都能完美呈现,操作便捷。核心功能全景:从交易到运营的全覆盖 新系统在功能上进行了大量优化和新增,形成了一个完整的商业闭环。 1. 用户与权限管理中心 完善的用户管理:用户封禁、余额手动调整等。 IP白名单:新增用户级IP白名单设置,为高安全需求的API调用提供额外保障。 2. 灵活的接口管理体系 主接口与轮询接口配置,实现高可用。 自定义接口文档,方便开发者快速接入。 3. 智能化的计费引擎 支持为每个接口单独设置费用(如0.01元/次)。 混合计费顺序:系统自动按 会员 -> 点数 -> 余额 的顺序扣除费用,最大化用户权益。 支持月度/季度/年度会员购买,以及点数充值。 4. 完善的订单与支付系统 集成支付宝、微信支付、余额支付。 修复了当面付和码支付的相关问题,支付流程更顺畅。 5. 会员增值与激励体系 每日签到:可灵活控制开关,并设置随机点数奖励(如1-50点),有效提升用户活跃度。 卡密兑换:新增卡密兑换功能,支持兑换会员、点数和余额,方便进行线下或活动推广。 6. 分销与提现机制 推介计划分润:后端可灵活控制分佣比例,助力用户裂变增长。 提现审核机制:余额提现可系统自动秒到,支付宝提现则由人工审核,兼顾效率与风控。 7. 数据统计与日志 详细的调用日志,方便进行问题排查和用量分析。 数据统计分析,为运营决策提供支撑。 快速部署与使用 项目下载包内附带了详细的视频教程,可以大大降低您的部署门槛。基本步骤如下: 环境准备:安装 Java 17、MySQL、Redis 环境。 导入项目:使用 IDE(如 IntelliJ IDEA)导入后端项目,使用 VSCode 等打开前端项目。 配置修改:根据视频教程修改后端配置文件(如数据库连接、Redis地址等)和前端API请求地址。 启动运行:先后启动后端服务(Spring Boot应用)和前端项目(执行 npm run dev)。 访问系统:通过浏览器访问前端地址,开始体验或进行初始化配置。 进阶建议:保护你的商业成果 当你基于此系统进行深度定制或成功运营后,保护核心代码和商业模式至关重要: 1. PHP代码加密平台 (php.javait.cn):虽然本系统为Java开发,但如果你有相关的PHP管理模块或计划开发配套工具,该平台提供的SG16等多种加密算法,可以有效防止你的PHP代码被反编译。 2. 数哈多应用授权系统 (auth.shuha.cn):若你计划将系统打包出售或为不同客户提供独立部署,该系统能帮助你对软件进行域名授权、时间限制等专业管理,保障你的软件收益。 开源与展望 开发者承诺,待功能进一步完善后,将在 GitHub 和 Gitee 上全面开源此项目。这意味着你可以持续关注并获得最新代码,甚至参与到项目的共建中。 立即下载体验 隐藏内容,请前往内页查看详情 温馨提示:如果在复制“快捷链接”或“推介计划邀请链接”时失败,请确保你的站点已开启 SSL (HTTPS),这是因为浏览器的安全策略对非安全链接的限制。